Canal+Flink+Kafka 同步业务表数据
背景
在分布式业务场景中,数据的实时同步、清洗与多下游分发是常见需求。
典型的流式架构 Canal+Flink+Kafka,结合业务表同步案例,拆解各组件特点、基本用法及全链路实践流程。
架构整体流程图
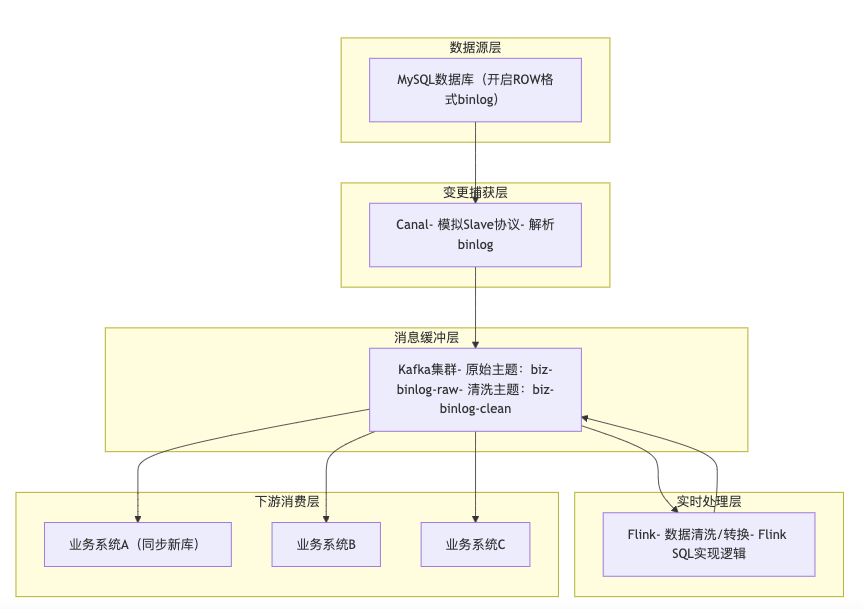
组件特点和用法
Canal
Canal:阿里的一款变更数据捕获工具,CDC(Change Data Capture)
-
特点:模拟 MySQL Slave 协议(从库同步主库数据),轻量高效捕获 binlog 变更,仅专注数据变更抓取,不做复杂处理,适配 MySQL 全量/增量同步场景。
-
基础用法:配置连接 MySQL 后,监听指定库表 binlog,解析为结构化数据(拿到变更前和变更后的数据),支持推送到 Kafka、RocketMQ 等中间件。
Kafka
-
特点:高吞吐量、高可靠性,兼具缓冲与解耦能力,可应对高峰流量削峰,实现一份数据多下游复用。
-
基础用法:通过主题(Topic)分区存储数据,支持多生产者/消费者并发读写。
Flink
Flink 作为实时计算引擎,在大数据处理上非常流行。
-
特点:擅长实时数据清洗、转换与计算,支持 Exactly-Once 语义,适配流处理场景,SQL 语法降低开发门槛。
-
基础用法:通过 Flink SQL 订阅 Kafka 主题,编写转换逻辑,输出到目标Topic,支持集群模式部署。
为啥引入Flink?
数据清洗、过滤、转换、计算等逻辑。
实践
单机版实践整个数据链路:
前置环境准备
- MySQL 开启 binlog(ROW 格式),设置唯一 server-id;
- 部署 Canal、Kafka、Flink 集群,确保网络互通,组件版本要兼容。
MySQL
- 修改 my.cnf 配置,重启 MySQL 生效,授权 Canal 连接权限(同步业务表所在数据库):
[mysqld]
log-bin=mysql-bin
binlog_format=ROW
server-id=1
binlog-do-db=biz_db # 替换为业务表所在数据库
gtid_mode=ON
enforce_gtid_consistency=ON
- 授权命令
CREATE USER canal@'%' IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO canal@'%';
FLUSH PRIVILEGES;
Kafka
创建topic,比如各 3 分区 1 副本(适配业务数据流量)
- 原始数据(topic: biz-binlog-raw)
- 清洗后数据(topic: biz-binlog-clean)
bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --topic biz-binlog-raw --partitions 3 --replication-factor 1
bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --topic biz-binlog-clean --partitions 3 --replication-factor 1
Canal
修改全局配置(canal.properties)指定 Kafka 输出,实例配置(instance.properties)绑定 MySQL 与监听业务表:
- canal.properties
canal.serverMode = kafka
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.default.topic = biz-binlog-raw # 关联业务原始数据主题
- instance.properties
canal.instance.master.address = 127.0.0.1:3306
canal.instance.mysql.slaveId = 1001
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
# 监听业务表 正则匹配哪些表
canal.instance.filter.regex = biz_db\\.t_biz_.*,biz_db\\.t_biz_detail_.*
- 启动 Canal
cd canal/bin && sh startup.sh
Flink
Flink承接原始数据topic和清洗后的topic,可通过Flink SQL 客户端创建表关联 Kafka,编写业务数据清洗转换逻辑:
-- 输入表(关联业务原始数据主题)
CREATE TABLE biz_binlog_raw (
id STRING COMMENT '业务ID',
biz_amount DECIMAL(10,2) COMMENT '业务金额',
biz_status TINYINT COMMENT '业务状态码',
create_time TIMESTAMP,
__op STRING COMMENT '操作类型'
) WITH (
'connector' = 'kafka', 'topic' = 'biz-binlog-raw',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'format' = 'json', 'scan.startup.mode' = 'latest-offset'
);
-- 输出表(关联业务清洗后数据主题)
CREATE TABLE biz_binlog_clean (
biz_id STRING, biz_amount DECIMAL(10,2),
biz_status_name STRING, create_time TIMESTAMP,
operate_type STRING, sync_time TIMESTAMP
) WITH (
'connector' = 'kafka', 'topic' = 'biz-binlog-clean',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'format' = 'json'
);
-- 业务数据清洗转换逻辑
INSERT INTO biz_binlog_clean
SELECT
id AS biz_id, biz_amount,
CASE WHEN biz_status=0 THEN '未完成' WHEN biz_status=1 THEN '已完成' ELSE '未知' END AS biz_status_name,
create_time, UPPER(__op) AS operate_type, CURRENT_TIMESTAMP AS sync_time
FROM biz_binlog_raw
WHERE id IS NOT NULL AND biz_amount > 0
GROUP BY id, biz_amount, biz_status, create_time, __op;
下游消费
业务系统A、B、C通过 Kafka 消费者订阅 biz-binlog-clean 主题,解析业务数据后同步到新库或按需使用,需做幂等处理避免重复消费的问题。
总结
数据同步链路各组件各司其职:
- Canal 专注变更捕获
- Flink 负责实时处理
- Kafka 实现缓冲解耦,扩展性强,既能适配业务表分库分表迁移场景,也能应对高峰流量,满足业务系统的多下游数据需求。