分布式缓存的一致性Hash
网站的伸缩性架构 – 分布式缓存的一致性Hash
一致性哈希
分布式缓存系统,k=>v缓存数据时经过一层路由算法,一般对key进行哈希运算,这个值和当前分布式缓存机器的编号对应起来。这样就能保证这个路由算法在存和取的时候保持一致。 这样发现关键点就是这个路由算法。通常,简易的算法就是取模。比如现在有3台机器。那就取key的哈希值(当成一个数字),模机器数 3,结果就是0、1、2,对应这三台机器。
取模这种方法通常是可行的,但是抛出一个问题再看: 在分布式缓存系统中,当前缓存中已经有很多存量的热点数据。假设3台,这时候,向缓存系统中添加一台机器,编号4。 取模这种路由算法,由原来模3,变成模4,这样导致大部分原来已经存在的热点数据都落不到原来的机器编号上了。这样扩容简单的追加一台缓存机器,本来是要提高性能,结果导致数据都打到DB上了,在如今缓存不可或缺的情况下,反而可能会把服务搞垮了。。
以上这种追加或者摘掉一台服务器,简单的取模路由算法是不可取的。有什么更好的算法支持么?让更多的存量缓存数据仍然落到原始编号机器上呢? 就是一致性哈希了。
一致性哈希算法,是通过一致性哈希环的数据结构实现的哈希映射。
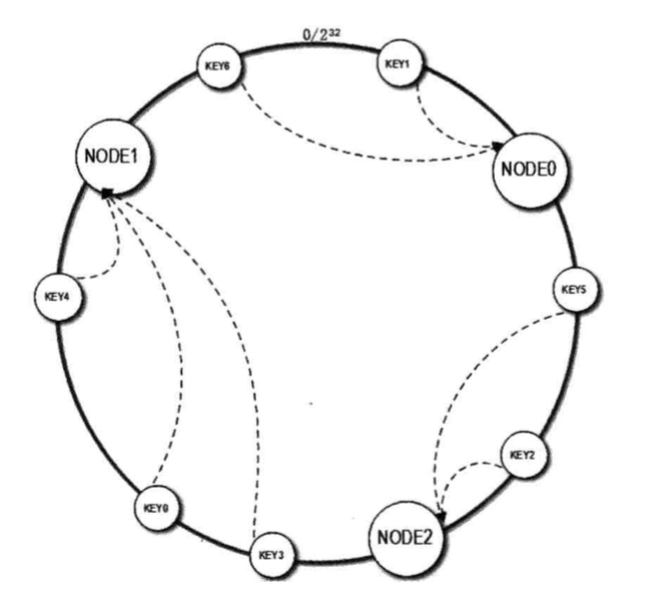
具体算法过程为:先构造一个长度为0~2^32的整数环(这个环被称作一致性Hash环), 根据服务器节点名称的Hash值(其分布范围同样为(0~2^32),将缓存服务器节点放罝在这个整数Hash环上。然后根据需要缓存的数据的KEY值计算得到其Hash值(其分布范围也同样为0~2^32),然后在Hash环上顺时针查找距离这个KEY的Hash值最近的缓存服务器节点,完成KEY到服务器的Hash映射查找。
这种绕环找节点的方式,使得扩容添加节点时,影响更少的存量热点数据。
如图:
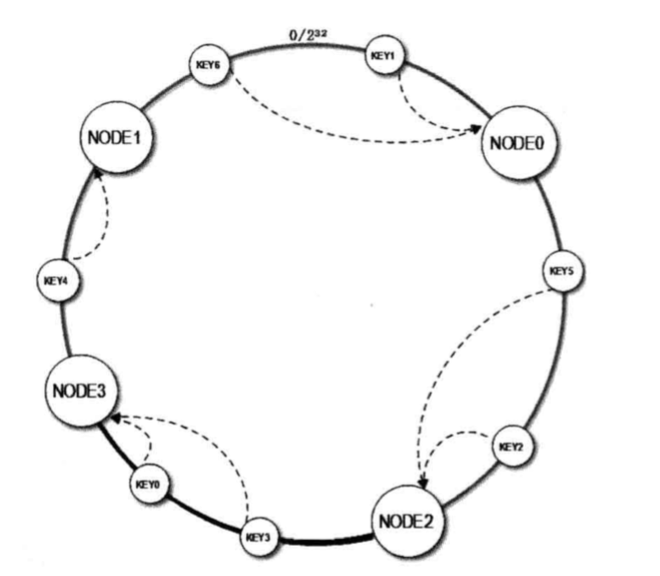
新增第4个节点node3,这样只影响了node2到node3路线上的缓存数据,只有大约1/4的数据受到影响。如果旧有节点数目够多,那么添加一个节点,可以见得受到影响的数据会更少。这种方式显然比取模算法更有优势。
具体应用中,这个长度是2^32的一致性哈希环通常使用二叉查找树实现,哈希查找过程实际上是在二叉查找树(二叉树是由所有机器节点哈希值组成)中查找不小于查找数(哈希的缓存key值)的最小数值。 – 很好理解,在整数环中顺时针找最近的,那意思就是找不小于查找数的最小值喽。
顺便再简单说下二叉查找树。 二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
- 若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值;
- 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
- 左、右子树也分别为二叉排序树;
【10】 <-- 根节点
/ \
【6】 【14】
/ \ / \
【4】 【8】【12】 【16】
以上就是分布式缓存中的一致性哈希。
参考
- 《大型网站技术架构》