Elasticsearch介绍
前段时间负责的一个群组相关的项目上线了,功能包含群组名称模糊检索和基于地理位置做同城、附近群检索的需求。这正是Elasticsearch大显身手的机会,接到项目需求,快速花时间调研ES的使用,如地理位置怎样存储和查询。
这里做个快速入门实战总结。
ES简介
Elasticsearch 是一个高可扩展的开源全文搜索和分析引擎。可以近实时地快速存储、搜索和分析大量数据,通常为具有复杂搜索功能和要求的应用提供支持。它底层是基于Apache Lucene(TM)(无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库)。
基本概念
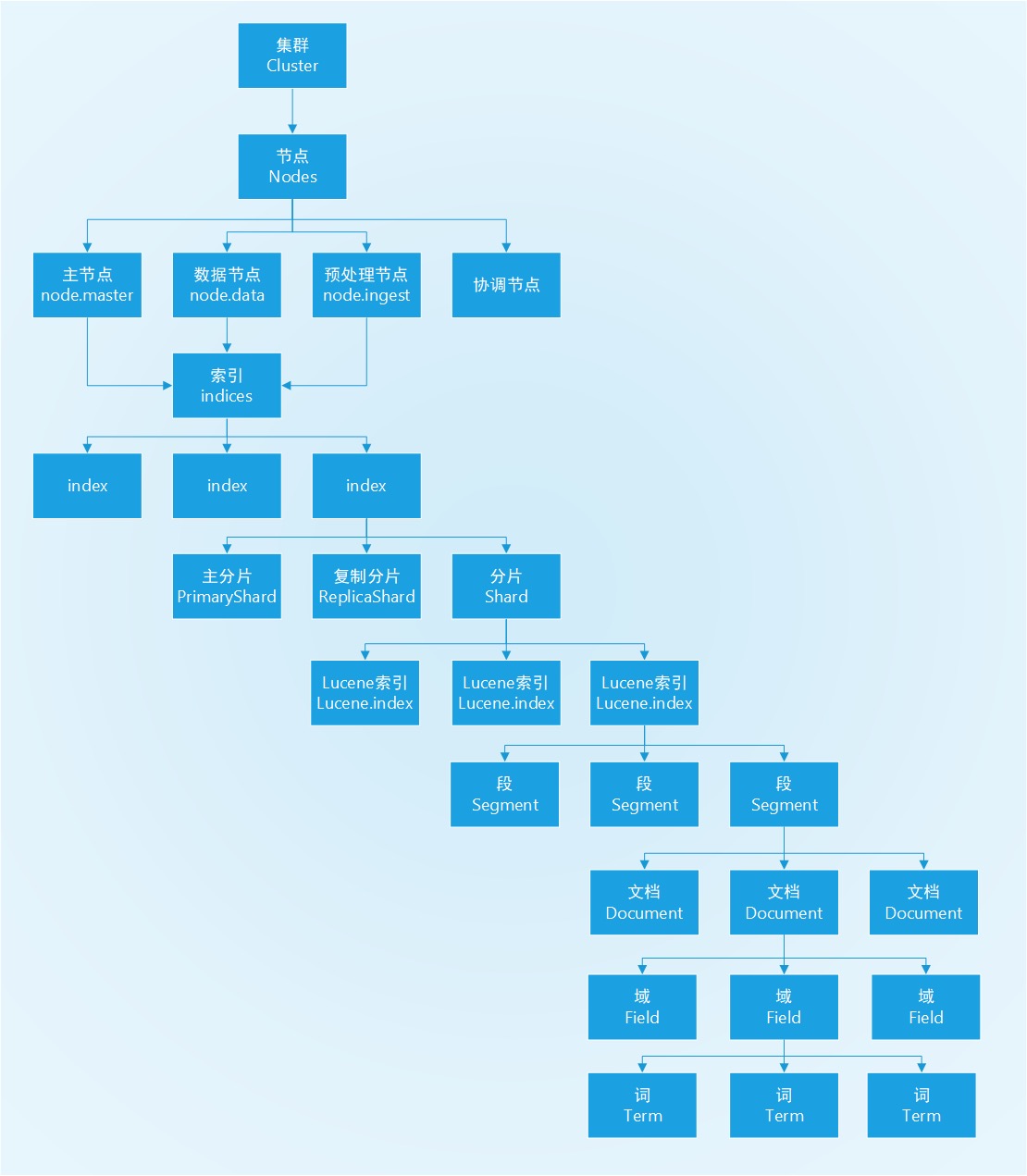
- 节点:一个运行中的 Elasticsearch 实例称为一个节点。
- 集群:集群是由一个或者多个拥有相同 cluster.name 配置的节点组成,它们共同承担数据和负载的压力。
- 索引:索引实际上是指向一个或者多个物理分片的逻辑命名空间。
- 分片:一个分片是一个Lucene 的实例,它本身就是一个完整的搜索引擎。一个分片是一个底层的工作单元,它仅保存了全部数据中的一部分。
- Lucene索引:段的集合,每一个段本身都是一个倒排索引,段中包含各文档。
了解ES的基本概念,对比MySQL
| 组件 / 项 | ES | MySQL | 备注 |
|---|---|---|---|
| 库 | Index | Databases | |
| 表 | Types | Tables | Elasticsearch 6.x版本废弃掉了Type |
| 行 | Documents | Rows | |
| 列 | Fields | Columes | |
| 表结构 | Mapping | Schema | |
| 扩展性 | Shard | 单实例分表,多实例分库等 | |
| 可用性 | Replicas副本 | 主备 | |
| 检索 | 倒排索引 全文检索 | 支持度不高 |
概念架构图
实践举例
Elasticsearch集群通常包含多个索引(indexes)(数据库),每个索引包含多个类型(types)(表),每个类型包含多个文档(documents)(行),每个文档包含多个字段(Fields)(列)。
以下为例子做增删改查API的部分入门实践:
- 索引(index):qmgroup
- 类型(type):groupinfo
创建索引
创建索引qmgroup,如指定分片数量(主分片数)、每个主分片的副本数等。
主分片数一般确定下来不会再改,否则路由会找不到原文档所在分片。副本数配置可随时调整,水平扩展以增加服务吞吐。
主分片数扩展的一种方式,可以新建一个索引(设置好分片数等),然后执行reindex,或者另一个方式是scroll遍历老索引数据bulk批量写到新索引里。
PUT /qmgroup
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
创建表结构mapping
Elasticsearch 支持如下简单域类型:
- 字符串: string
- 整数 : byte, short, integer, long
- 浮点数: float, double
- 布尔型: boolean
- 日期: date
当索引一个包含新域的文档(之前未曾出现) Elasticsearch 会使用 动态映射(dynamic mapping) ,通过JSON中基本数据类型,尝试猜测域类型,使用如下规则:
| JSON type | 域 type |
|---|---|
| 布尔型: true 或者 false | boolean |
| 整数: 123 | long |
| 浮点数: 123.45 | double |
| 字符串,有效日期: 2014-09-15 | date |
| 字符串: foo bar | string |
默认, string 类型域会被认为包含全文。就是说,它们的值在索引前,会通过一个分析器,针对于这个域的查询在搜索前也会经过一个分析器。
string 域映射的两个最重要属性是 index 和 analyzer 。
index 属性控制怎样索引字符串。它可以是下面三个值:(string 域 index 属性默认是 analyzed )
| index属性类型 | 含义 |
|---|---|
| analyzed | 首先分析字符串,然后索引它。换句话说,以全文索引这个域。 |
| not_analyzed | 索引这个域,所以它能够被搜索,但索引的是精确值。不会对它进行分析。 |
| no | 不索引这个域。这个域不会被搜索到。 |
举例:由于地理坐标点不能被动态映射自动检测,需要显式声明对应字段类型为 geo-point,如下:
PUT /qmgroup
{
"mappings": {
"groupinfo": {
"properties": {
"location": {
"type": "geo_point"
},
"tag" : {
"type" : "string",
"index": "not_analyzed"
}
}
}
}
}
添加文档doc
| 语句 | 是否指定文档id | Method | 备注 |
|---|---|---|---|
| PUT /index_name/type_name/id | 指定id | PUT | 如从数据库同步到ES,指定原表中的业务唯一id等 |
| POST /index_name/type_name/ | 不指定id | POST | ES自动生成唯一id |
PUT /qmgroup/groupinfo/1
{
"gname": "名字x",
"location": {
"lat": 40.12,
"lon": -71.34
}
}
PUT /qmgroup/groupinfo/2
{
"gname": "名字y",
"location": {
"lat": 40.52,
"lon": -71.64
}
}
删除文档doc
- 根据docID 删除一条
curl -XDELETE localhost:9200/index/type/documentID
curl -X DELETE -u username:passwd "http://10.10.11.11:9200/qmgroup/groupinfo/2035"
- 根据where条件 删除多条
qmgroup/groupinfo/_delete_by_query
{
"query": {
"term": {
"uid": 1111111
}
}
}
修改文档
- 更新部分字段、插入
- path路径中的 _update 一定要有,否则会全部覆盖更新所有字段
- 需要注意的是,如果upsert成功,http_code返回码是201,而非200。注意这一点区别,避免无谓的重试等操作。
POST qmgroup/groupinfo/2/_update
{
"doc": {
"gname": "test"
},
"doc_as_upsert": true
}
- 批量更新bulk 注意\n换行 强制
注意一条请求分两行,第一行说明操作和元数据,第二行是操作数据。
$ curl -X POST -u username:passwd "http://10.10.11.11:9200/qmgroup/groupinfo/_bulk" -H 'Content-Type: application/json' -d'
{ "update": { "_id": "888" }}
{"doc":{"usernum" : 221},"doc_as_upsert":true}
{ "update": { "_id": "9999" }}
{"doc":{"usernum" : 111},"doc_as_upsert":true}
'
查询检索文档
1. 模糊搜索
{
"query": {
"match": {
"name": {
"query": "tonyn",
"fuzziness": "AUTO",
"operator": "and"
}
}
}
}
2. 指定获取字段返回
利用_source
{
"query": {
"term": {
"uid": 31116
}
},
"_source": [
"groupid"
],
"size": 100
}
3. 查count
qmgroup/groupinfo/_count
{
"query": {
"range": {
"usernum": {
"gte": 100,
"lt": 200
}
}
}
}
4. 聚合操作 如group by xx
{
"size": 0,
"aggs": {
"gtype_agg": {
"terms": {
"field": "gtype",
"size": 15 // 默认是获取top 10的指定field
}
}
}
}
$ curl -u uname:passwd -XGET "http://10.11.11.11:8200/qmgroup/groupinfo/_search?pretty" -d '
{
"size": 0,
"aggs": {
"gtype_agg": {
"terms": {
"field": "gtype",
"size": 15 // 默认是获取top 10的指定field
}
}
}
}'
5. 查文档中(不)含有某字段
ES支持非结构化,非固定表结构的文档。有的文档可能包含某field,有的可能没有。
如下,查询 没有gtype 字段的文档:
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "gtype"
}
}
]
}
}
}
6. 地理位置查询
查询距离 排序
qmgroup/groupinfo/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "160km",
"location": {
"lat": 40,
"lon": -70
}
}
}
}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 40,
"lon": -70
},
"order": "asc",
"unit": "km",
"distance_type": "plane"
}
}
]
}
7. 滚屏操作
类似 MySQL分页方式,利用 offset(from),获取每一页。
实际操作发现,每次到1万条数据以后,就拉取失败了。返回500的状态码,客户端查询,发现报错如图。

报错原因,max_result_window有最大限制,如果想获取大量数据集合,ES有更高效的方式,就是scroll api的方式。
两阶段用法:
- 获取scrollId
scroll=1m 给用户滚动操作的时长,1分钟。
POST /twitter/tweet/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
- 利用scrollId 再继续滚动获取
第二次请求的path路径,不需要再指定index,只有 /_search/scroll
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
每次利用上一次返回的scrollId,获取下一次的返回,直到 hits是空