Kafka入门介绍
Kafka是什么
Kafka最初是LinkedIn公司开发的一个内部基础设施系统,后开源到Apache软件,至今也已经活跃多年,被广泛的用于消息流式处理的场景。Kafka作为流式平台,支持发布和订阅数据流,并把消息保存起来、进行处理。
Kafka的几个概念
了解Kafka之前还是要先搞明白几个术语。其基本的组成:
-
主题(topics)
Kafka所有的消息都属于一个topic,发送一个消息要指定一个topic,同样接收一个消息也要指定其topic。
-
分区(partition)
Kafka的主题被分为多个分区,分区是基本的数据块,分区存储在单个磁盘上。多个分区分散在多个broker下,可以有效负载。
-
生产者(producers)
producer是产生消息推到Kafka的topic。
-
消费者(consumers)
consumer从Kafka的指定topic拉消息读取。
-
机器实例(brokers)
每个broker就是kafka集群下的某个机器节点。每个broker可能有一个或多个partition。
-
消费者组(consumer group)
一个消费者群组由多个消费者组成。如一个topic下有多个partition,每个partition只能被群组内的一个消费者消费。比如没有群组这功能,那么订阅某topic的多个消费者,每一个都会收到topic下的全部消息。
-
消息偏移量(offset)
消息落盘在每个partition上有自己唯一的offset,从0~n整数递增。每个消费者消费时都会记录自己在某个partition上的的消息读取的偏移量。当发生重均衡或者崩溃恢复时,会利用这个偏移量知道自己消费到哪条数据了。
单独看这些概念,很难形成一个对Kafka的全局概念。几图胜千言~
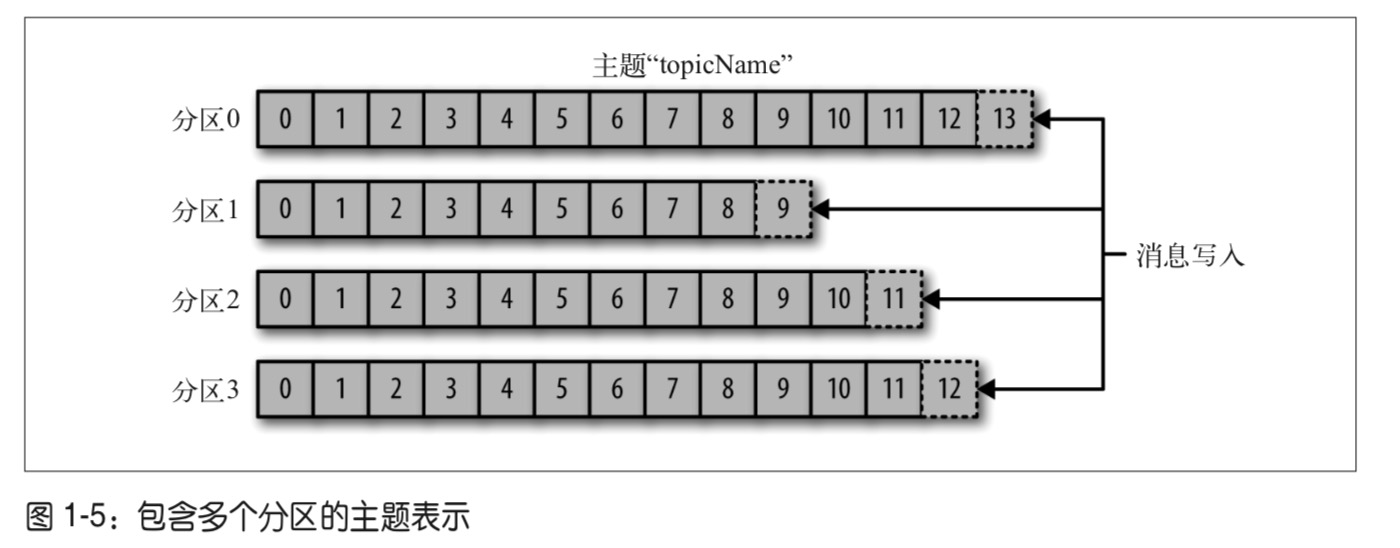
主题与分区
一个主题分为多个分区,每个区分就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
分区可以分布在不同的broker上,也就是说,一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。
生产者与消费者
生产者创建消息,并发布到某个topic。默认情况消息会均衡负载到topic下所有分区上。通常也会指定某条消息下发到某个分区,这是利用消息key和分区器实现。分区器为键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。
消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的offset来区分已经读取过的消息。在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。
比如将Kafka配置为保留一天的消息,而消费者down掉的时间超过一天,那么该消费者将丢失了消息。如果消费者down了一个小时,当恢复的时候它可以从其最后一个已知偏移量开始再次读取消息。 从Kafka的角度来看,它没有保持任何关于消费者从某个主题中阅读的内容的状态。
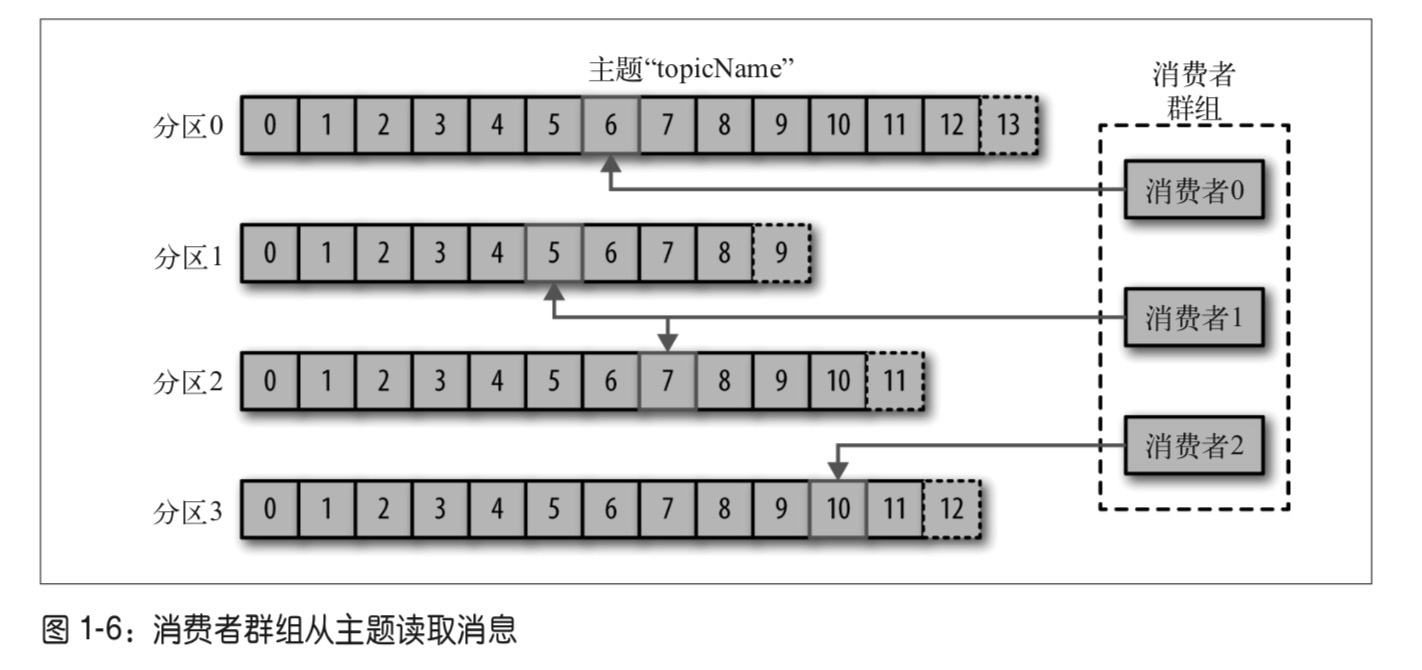
消费者与消费者组
如果有两个消费者订阅某一个主题,那么每个消费者都会收到主题内的全部消息。有一种场景要求多个消费者中每个消费者读取该主题的一部分消息,这就是消费者组了。
多个消费者可以组合成一个消费者组来订阅某个topic,组里的每个消费者都从唯一的分区中读取内容,整个组作为一个整体来消费主题中的所有消息。
如果组内消费者数量大于分区数量,那么某些消费者将处于空闲状态;如果分区比消费者更多,那么会有某些个消费者将从多个分区接收消息;如果具有相同数量的消费者和分区,则每个消费者都从一个分区中按顺序读取消息。
下图中主题有4个分区,消费者组有3个。说明要有某些个消费者读取多个分区,但也一定满足一个分区只能被一个消费者消费。这里是分区1和2,被消费者1消费。
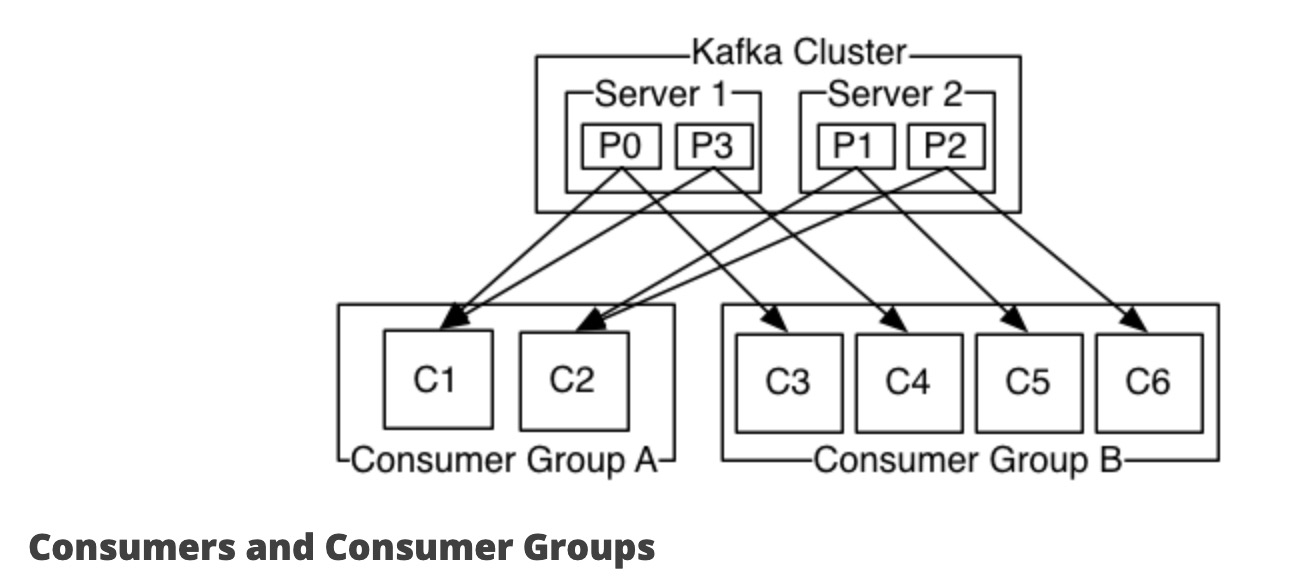
下图中,一个主题由4个分区组成:server1上是分区0和分区3,server2上是分区1和分区2。由两个消费者组A和B:A有2个消费者,B有4个消费者。 两个消费者组都订阅了该主题,那么组A中每个消费者读取两个分区消息,组B中每个消费者读每个分区的消息。
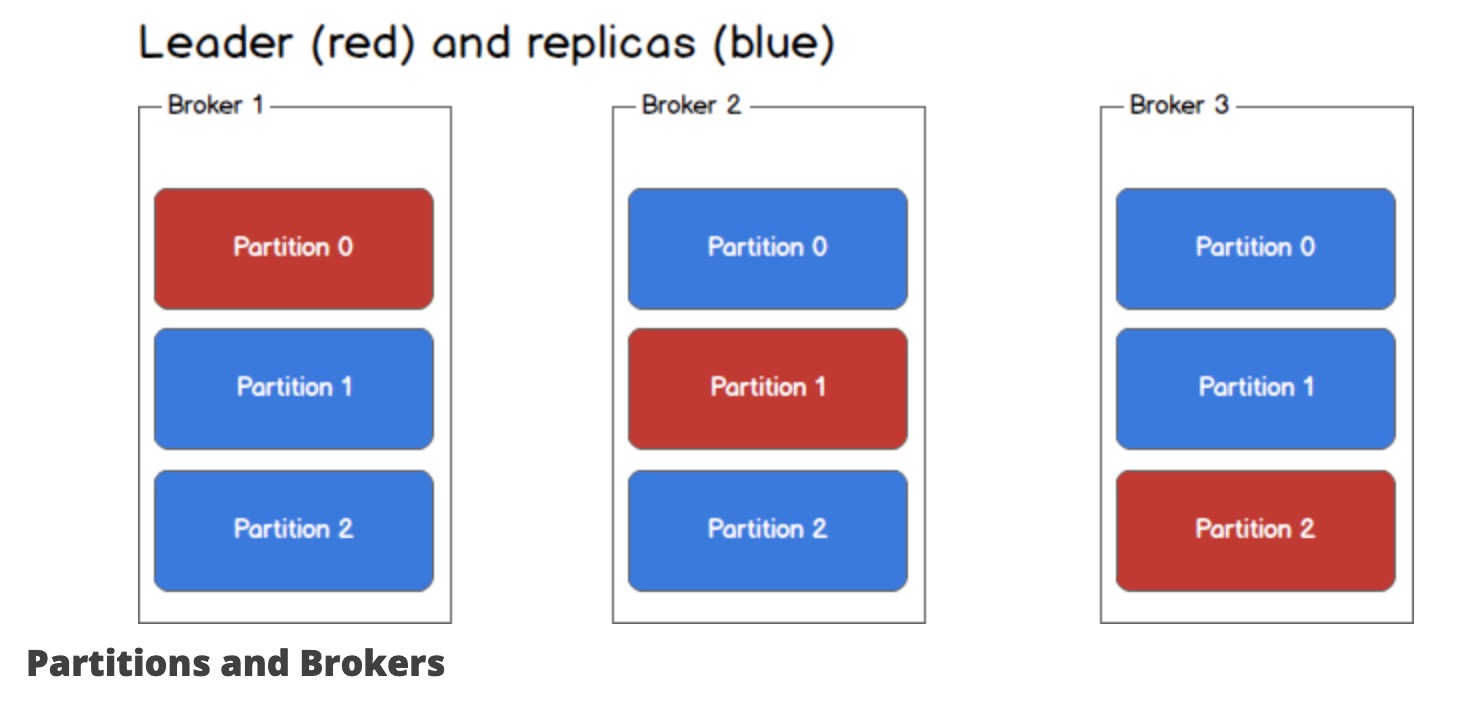
分区与broker
每个broker都可以有多个分区,并且每个分区都可以是主题的leader或副本。所有对主题的写入和读取都经过leader,并且leader协调去更新副本。 如果leader挂了,那么副本将接管新的leader。
下图一个主题有3个分区,主题横跨3个broker,每个broker有1个leader分区和2个副本分区。
下图描述消息发布过程。该条消息被路由写到分区0的leader中,leader并同步到另外两个机器的副本上。
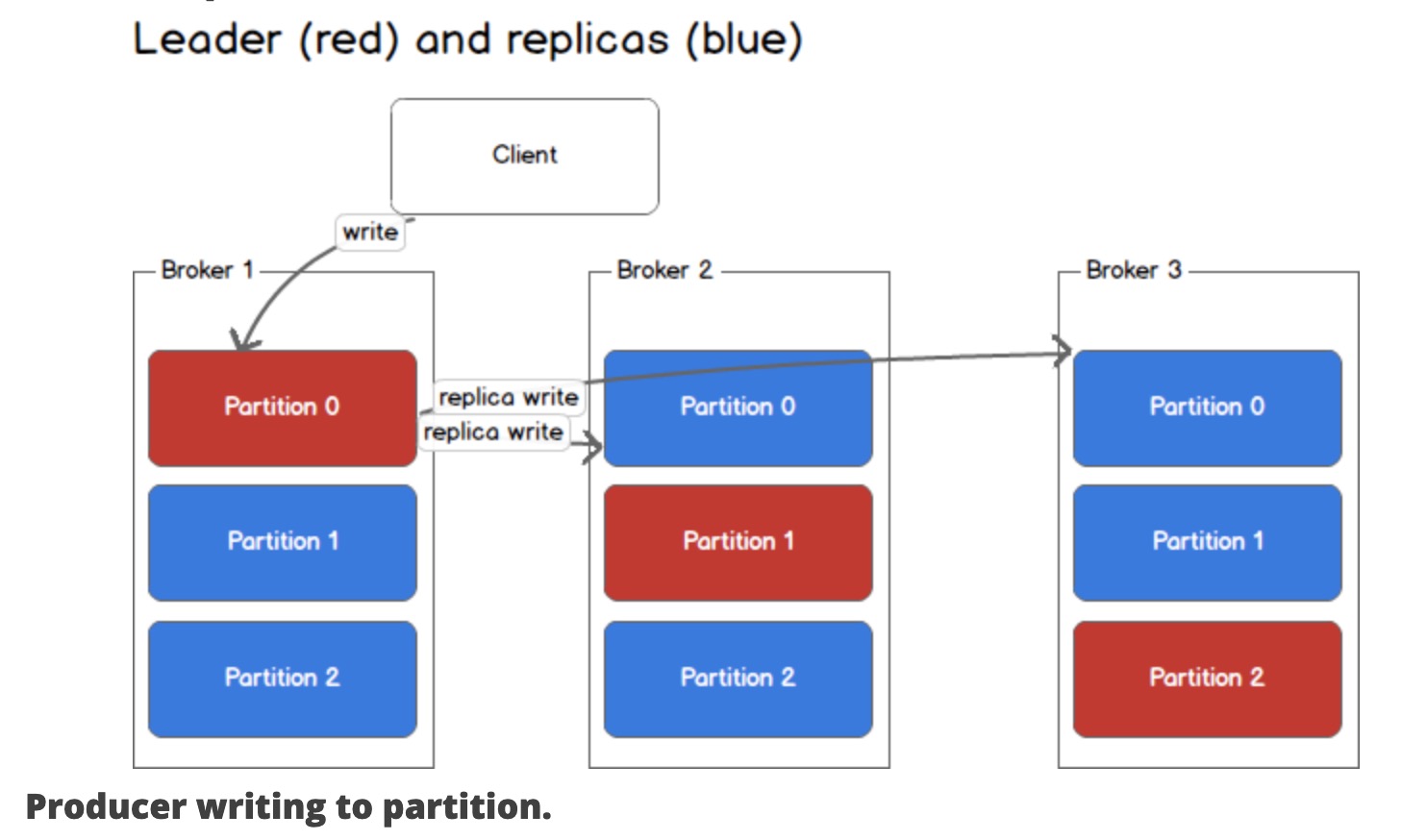
一致性和可用性
Kafka对数据一致性和可用性做出以下保证:
(1)发送到主题分区的消息将按照发送的顺序附加到提交日志中;
(2)单个消费者实例将按照出现的顺序读取到消息日志,只能读取已经提交的消息;
(3)当所有同步副本都已将消息追加到其日志时,才是『已提交』消息;
(4)只要至少有一个同步副本处于激活状态,任何『已提交』的消息都不会丢失。
1-2保证了消息在每个分区中是有序的,因为一个主题一般包含多个分区,因此无法在整个主题范围内保证消息的顺序。
3-4保证可以获取到已提交的消息。在Kafka中,被选为leader的分区负责将收到的所有消息同步到副本中。副本确认消息后,才会视为该副本同步了。leader挂了后,Kafka通过Zookeeper选举新的leader,短暂期间会有leader不可用错误,此时生产者要处理好异常并做出重试避免消息丢失。
下图描述Kafka集群的分区复制过程:
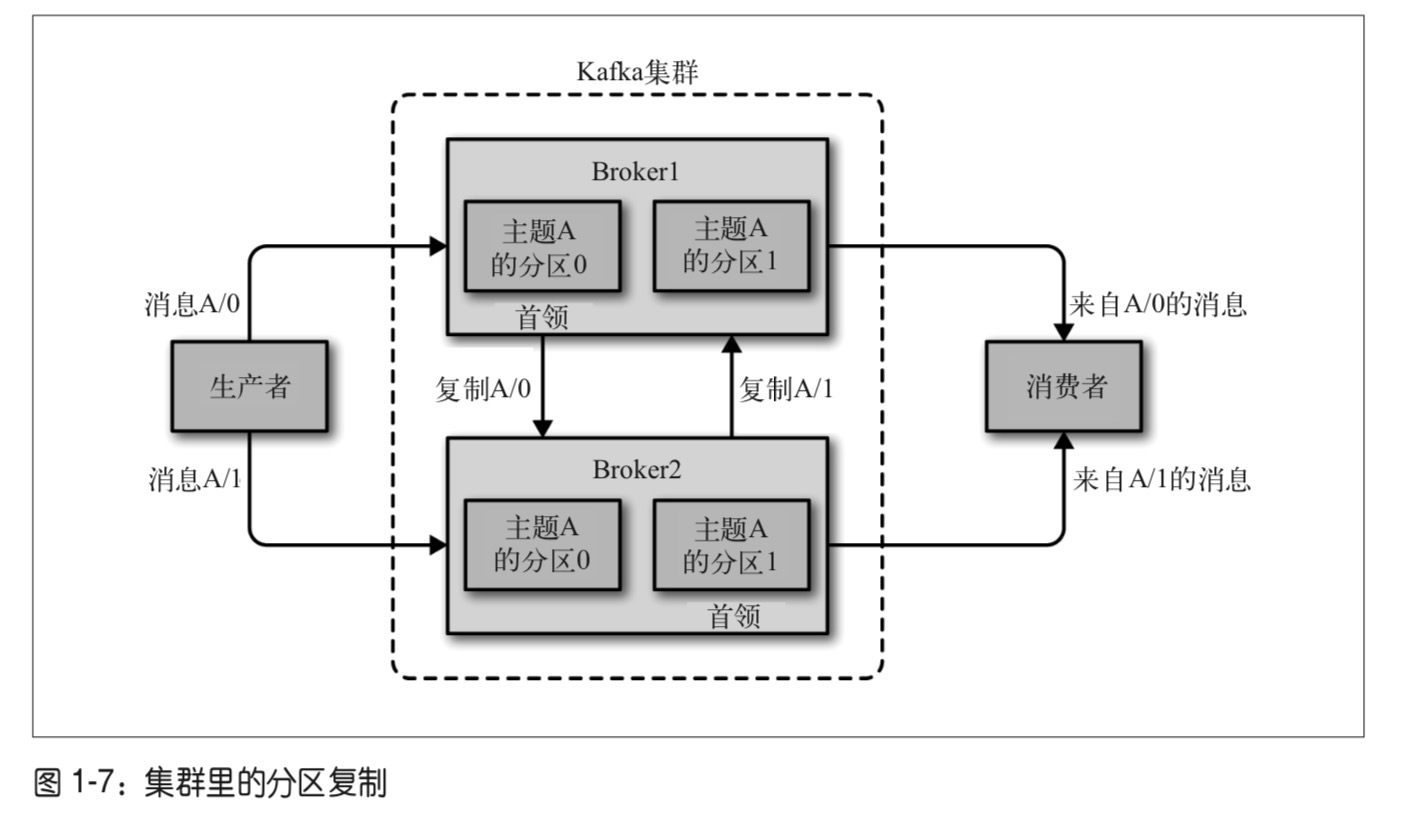
与Kafka群集进行通信时,所有消息都会发送到分区的leader。leader负责将消息写入其自己的同步副本中,一旦提交了该消息,则负责将消息传播到不同broker上的其他副本中。每个副本都确认他们已收到消息,才被视为同步了。
一致性
生产者和消费者均支持可配置的一致性级别。
生产者
三种可选模式,根据自己场景可接受的一致性和吞吐量考虑做出取舍。
- acks=0 不等确认返回。通过网络把消息发送出去,那么就认为消息已成功写入Kafka。 吞吐量高,消息很可能有丢失
- acks=1 仅等待leader副本确认。leader收到消息并把它写入到分区数据文件(不一定同步到磁盘上)时 会返回确认或错误响应。
- acks=2 等待所有副本确认同步。 吞吐量最差。
消费者
消费者的一致性主要在偏移量提交上做出权衡。
- at most once 消费者从分区读出消息,并提交读取的偏移量,然后再处理消息。如果提交偏移量后,消费者挂了,那么这些消息还没处理。但是当恢复消费的时候,再拉数据就从上次提交的偏移量后边开始,导致消息丢失处理。
- at least once 消费者从分区读出消息,处理消息,再提交处理完消息的偏移量。有一种case,当处理完消息后,消费者挂了,偏移量没提交出去。再次恢复时候,会重复消费这个消息,但不会丢失消息。
- once 消费者的处理消息和提交偏移量放在一个事务里,保证崩溃恢复的时候,不会丢失和重复消费。这种处理影响吞吐量。
总结
这里只是对Kafka组件的入门介绍,主要是对内部概念的讲解,有个大体的认知。使用过程中还是要做到熟悉Kafka各种配置和常用模式,了解自身应用场景需求。
参考:
- 《Kafka权威指南》
- Kafka 介绍