Kafka server的线程模型与网络模型
Kafka 的标签高吞吐、高并发、高可扩展等等,为什么它有这么好的性能,我们看看它的server 线程模型和网络模型。
Kafka 性能为什么这么好
Kafka 有着高吞吐、高并发的特性,是什么支撑它这么强悍的性能呢?除了分布式部署的特性外,我们主要来看单机Broker实例是如何提升性能的?
- 磁盘顺序写
- 批处理
- 零拷贝技术 sendfile
这几点,我们大都知道。还有一点,就是它的 server 的网络/线程模型的分层架构,也是它性能强悍的重要方面。
Reactor 模型
类似NGINX、Redis、Netty、Kafka 这种都算是网络服务器,基本不可避免的都会使用 Reactor 模型。
- IO 模型:IO 多路复用 + 非阻塞 IO
- 线程模型:单线程、多线程(线程池)等
- Reactor:单 Reactor、多 Reactor (主从 Reactor)
理解 Reactor 无非就是这几点,如果基础不牢的同学,建议先把 几种基本的IO 模型(尤其学习 epoll 使用)、并发编程(线程池技术)弄清楚。
说到 Reactor,有一个非常好的资料 来自 Doug Lea的 Scalable IO in Java
Multiple Reactors
其实 Kafka 的 Reactor 实现,和这里的 Multiple Reactors 非常类似。
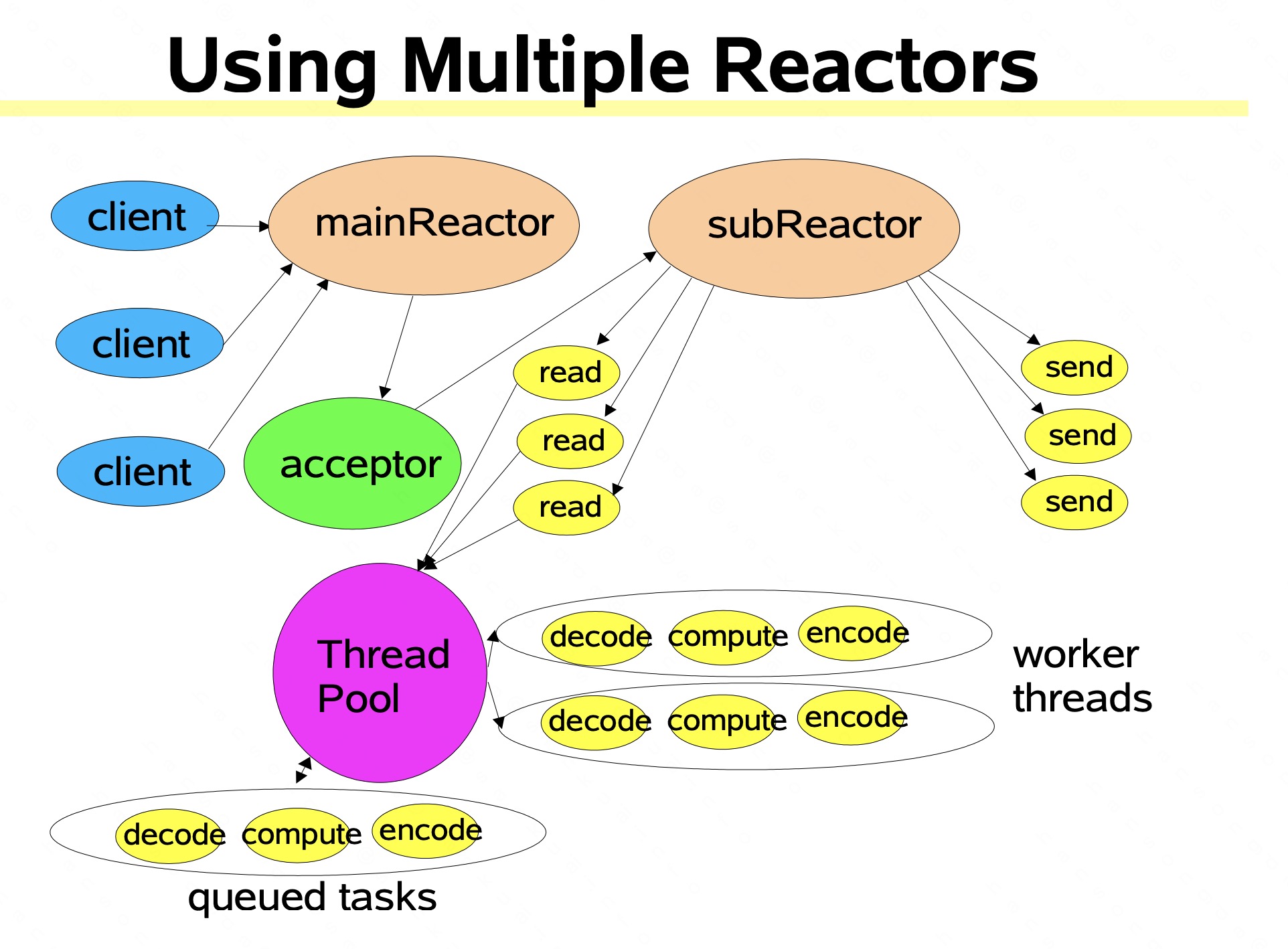
简要介绍这几个实体:
-
mainReactor
只负责监听 listenfd 读事件,accept() 后拿到 客户端的连接描述符 clientfd
-
subReactor
和 listenfd 区分开,subReactor 关注上边生成的 clientfd 的可读可写事件,如 读出客户端发送的请求,写回客户端响应数据。
这里的 subReactor 也可以做多个线程,Kafka 的 Processor 线程池就是扩展了这个。
-
ThreadPool
这是真正负责业务处理的线程,一些IO处理、落盘处理等、包括生成给客户端的响应信息等(当然发送还是交给subReactor 线程)。
网络模型与线程模型
Kafka 的网络模型自然也是 Reactor了,但 Kafka 的实现还是很值得学习和借鉴的。
这里以 Kafka v0.10.0 版本源码为例分析
图示 图片来自图解Kafka
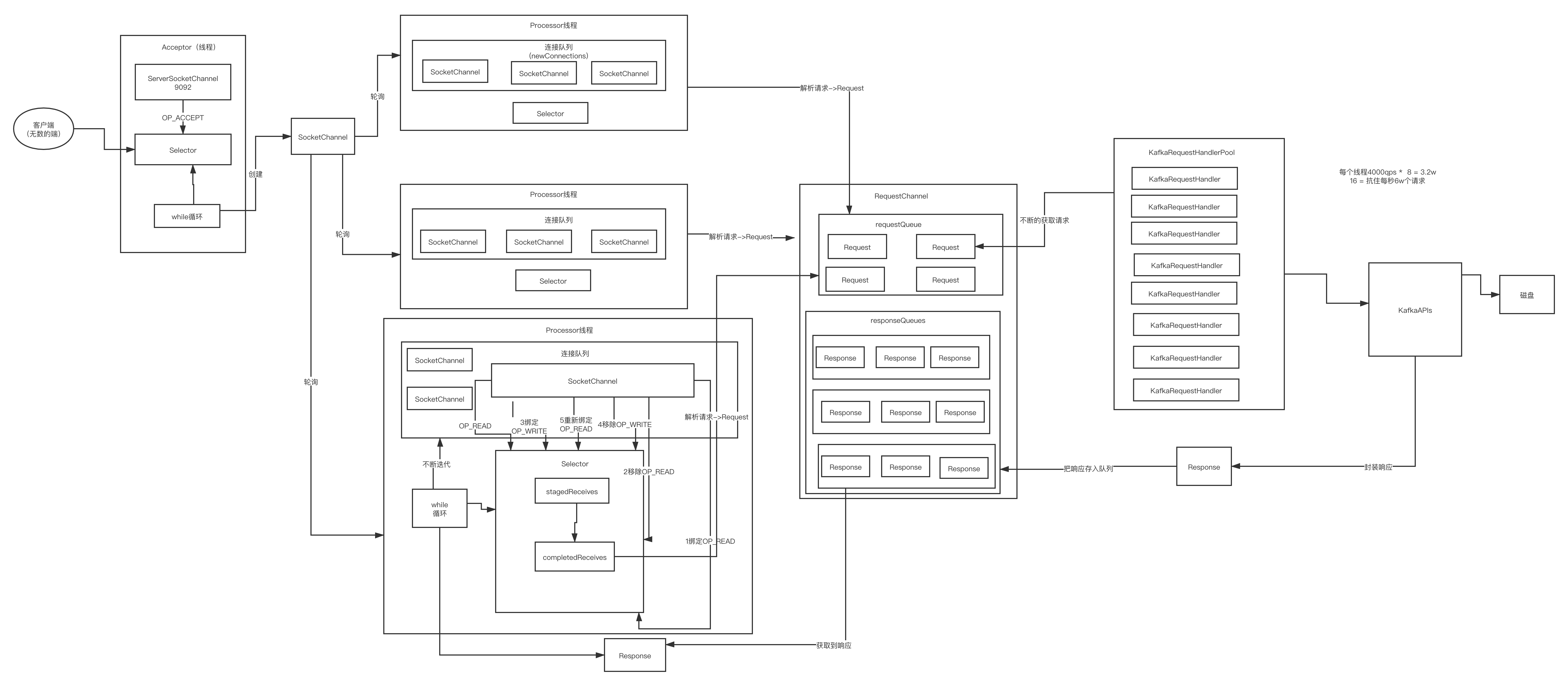
流程分析
-
Acceptor 线程,即 MainReactor,监听listenfd 的读事件,accept() 生成 clientfd 并轮询交给 一个 Processor 线程。
-
Processor 线程自己的 subReactor, 关注这些 clientfd 的读事件,即客户端发过来的数据。
-
2中读取解析客户端数据 构造 Request 数据结构,把Request 放到 RequestChannel的 requestQueue 中 (充当缓冲)。
注意这里就要把 2 中关注的可读事件取消,准备关注可写事件了
-
KafkaRequestHandlerPool 是 IO 线程池,处理具体业务请求。从 requestQueue 中拿客户端请求做处理。
-
4中处理完,构造Response 数据结构,并放到 RequestChannel的 responseQueue 中。
注意这里开始关注 可写事件了
-
Processor 线程读取到可写事件,从 responseQueue 中拿数据,send 给客户端。
注意这里又会取消关注 可写事件,准备关注可读事件了,如此往复。
源码
几种线程操作的关键步骤,加一些注释
Acceptor 线程
/**
* Thread that accepts and configures new connections. There is one of these per endpoint.
*/
private[kafka] class Acceptor(val endPoint: EndPoint,
val sendBufferSize: Int,
val recvBufferSize: Int,
brokerId: Int,
processors: Array[Processor],
connectionQuotas: ConnectionQuotas) extends AbstractServerThread(connectionQuotas) with KafkaMetricsGroup {
private val nioSelector = NSelector.open()
val serverChannel = openServerSocket(endPoint.host, endPoint.port)
this.synchronized {
processors.foreach { processor =>
Utils.newThread("kafka-network-thread-%d-%s-%d".format(brokerId, endPoint.protocolType.toString, processor.id), processor, false).start()
}
}
/**
* Accept loop that checks for new connection attempts
*/
def run() {
// 关注新连接 accept 事件
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)
startupComplete()
try {
var currentProcessor = 0
while (isRunning) {
try {
val ready = nioSelector.select(500)
if (ready > 0) {
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
while (iter.hasNext && isRunning) {
try {
val key = iter.next
iter.remove()
if (key.isAcceptable)
// accept 里把新建连接的 fd,交给 subReactor 即某一个 Processor 线程
accept(key, processors(currentProcessor))
else
throw new IllegalStateException("Unrecognized key state for acceptor thread.")
// 轮询下一个 Processor
currentProcessor = (currentProcessor + 1) % processors.length
} catch {
case e: Throwable => error("Error while accepting connection", e)
}
}
}
}
catch {
...
}
}
} finally {
...
}
}
/*
* Accept a new connection
*/
def accept(key: SelectionKey, processor: Processor) {
val serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]
// 获取新连接
val socketChannel = serverSocketChannel.accept()
try {
connectionQuotas.inc(socketChannel.socket().getInetAddress)
// 非阻塞IO 搭配 IO复用 食用:)
socketChannel.configureBlocking(false)
socketChannel.socket().setTcpNoDelay(true)
socketChannel.socket().setKeepAlive(true)
socketChannel.socket().setSendBufferSize(sendBufferSize)
// 把新连接fd 给了这个 processor
processor.accept(socketChannel)
} catch {
case e: TooManyConnectionsException =>
info("Rejected connection from %s, address already has the configured maximum of %d connections.".format(e.ip, e.count))
close(socketChannel)
}
}
Processor 线程
Handler 线程池
RequestChannel 数据结构
参考
- Scalable IO in Java
- Kafka v0.10.0 github
- 《图解Kafka》
- 《Kafka核心源码解读》