Kafka 深入理解
问题一:消费者自动提交的机制,是有单独的自动提交线程么?
实际不是的,自动提交还是隐藏在每一次的poll方法里,还是一个线程。
auto.commit.interval.ms只是确定了提交位移的最小时间间隔,而提交位移的动作是隐藏在每一次的poll方法中的,这一次的poll会先提交上一次的位移,poll方法的时候,如果时间间隔大于auto.commit.interval.ms设置的时间间隔,就会进行位移提交,如果小于,则不会进行提交。当然,如果过了auto.commit.interval.ms的时间间隔,仍然没有下一次的poll方法,那么依然不会进行位移提交。
问题二:自动提交下的重复消费 举例
kafka重复消费的一个场景:生产环境遇到有一条同样的消息,一样的partition,一样的offset,被不同的消费者消费了。
简单描述:
qms01机器上线,上线过程中先停服,此时消费者挂掉,导致rebalance,原本属于这个机器消费的part被分给了qms02机器
qms02消费到了这条消息,在没有来得及自动提交offset时。qms01机器启动了,又再次发生rebalance,partition 2又分给了qms01
由于part2的offset还是qms01未提交的,所以qms02又重复消费了这条消息。
消费者一定要做好幂等,重复消费很难避免。
问题三:如何理解ISR中的参数 replica.lag.time.max.ms?
追随者副本不提供服务,只是定期地异步拉取领导者副本中的数据而已。既然是异步的,就存在着不可能与Leader实时同步的风险。
ISR不只是追随者副本集合,它必然包括Leader副本。甚至在某些情况下,ISR只有Leader这一个副本。
Kafka判断Follower是否与Leader同步的标准,不是看相差的消息数,而是另有“玄机”。
这个标准就是Broker端参数replica.lag.time.max.ms参数值。这个参数的含义是Follower副本能够落后Leader副本的最长时间间隔,当前默认值是10秒。这就是说,只要一个Follower副本落后Leader副本的时间不连续超过10秒,那么Kafka就认为该Follower副本与Leader是同步的,即使此时Follower副本中保存的消息明显少于Leader副本中的消息。
ISR是一个动态调整的集合,而非静态不变的。
todo: 如何理解或者如何判断 只要一个Follower副本落后Leader副本的时间不连续超过10秒?? 比对最后一条消息的时间戳?
我理解是 follower来fetch leader时,带上上一条的时间戳,leader和最新的比较。
If a follower hasn’t sent any fetch requests or hasn’t consumed up to the leaders log end offset for at least this time, the leader will remove the follower from ISR.
问题四:消费组里的每个消费者消费到哪条消息了,在哪记录? 怎么记录的?
kafka早期,是记录到zk里的。但zk组件是干元数据存储共享的,不适合高频写入。后期,改到一个专门的topic记录所有消费者的消费位移。
位移topic下怎么记录消息的<k,v> ? 位移主题的Key中保存3部分内容:<Group ID,主题名,分区号>,v是offset。
为什么是这三个组成的key?
- 消费者具体是消费某个topic下的分区,所以消费者消费到哪条消息了,是指这个分区被消费到哪条消息了。 因此需要分区号
- 虽然一个分区只给一个组下的消费者,但是一个分区可能对应多个消费组。 因此,位移主题下的key要有消费组id。
- 又因为一个组id可能订阅多个topic,所以key只有组id不行,还要有topic。
问题五:重平衡触发流程是啥样的?
通常什么情况下触发重平衡:
消费者数量变化(增加【服务机器上线】、减少【服务机器下线】)
topic的分区数变化 (增加分区 导致消费者要重新平衡,Kafka当前只能允许增加一个主题的分区数。当分区数增加时,就会触发订阅该主题的所有Group开启Rebalance)
订阅的topic数量发上变化(Consumer Group可以使用正则表达式的方式订阅主题,比如consumer.subscribe(Pattern.compile(“t.*c”))就表明该Group订阅所有以字母t开头、字母c结尾的主题。在Consumer Group的运行过程中,你新创建了一个满足这样条件的主题,那么该Group就会发生Rebalance)
值得注意的是,一个消费者组 是可以订阅多个topic的。
重平衡过程是如何通知到其他消费者实例的?
答案就是,靠消费者端的心跳线程(Heartbeat Thread)。 当协调者决定开启新一轮重平衡后,它会将“REBALANCE_IN_PROGRESS”封装进心跳请求的响应中,发还给消费者实例。当消费者实例发现心跳响应中包含了“REBALANCE_IN_PROGRESS”,就能立马知道重平衡又开始了,这就是重平衡的通知机制。
重平衡一旦开启,Broker端的协调者组件就要开始忙了,主要涉及到控制消费者组的状态流转。
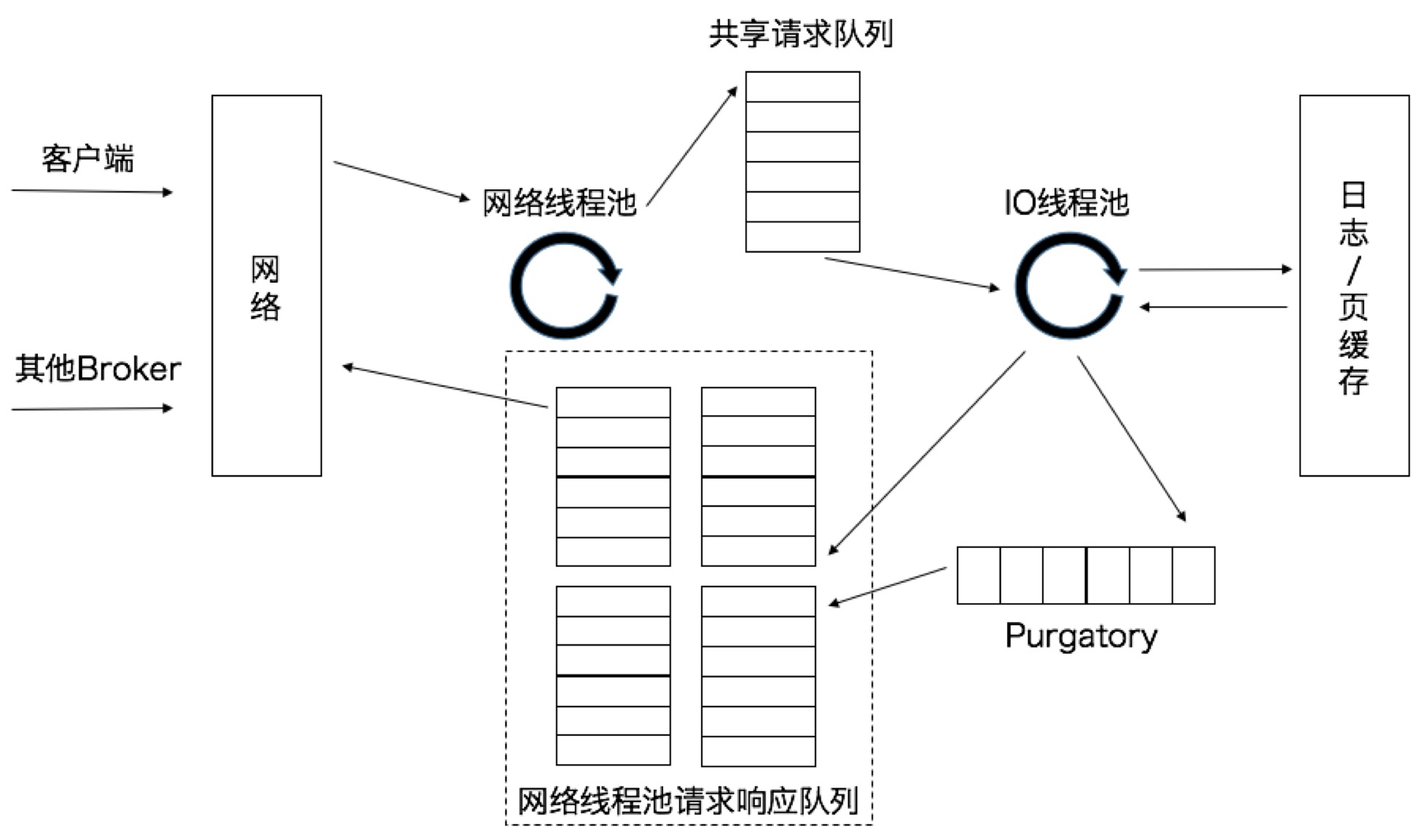
问题六:kafka server端对一个请求是如何处理的? 它的线程模型是啥样的?
Reactor入门教程:https://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
todo 为什么要有网络线程池+IO线程池?
理解 :网络线程池 对应主从Reactor;IO线程池 worker角色 负责处理业务 如落日志等。
类似于: 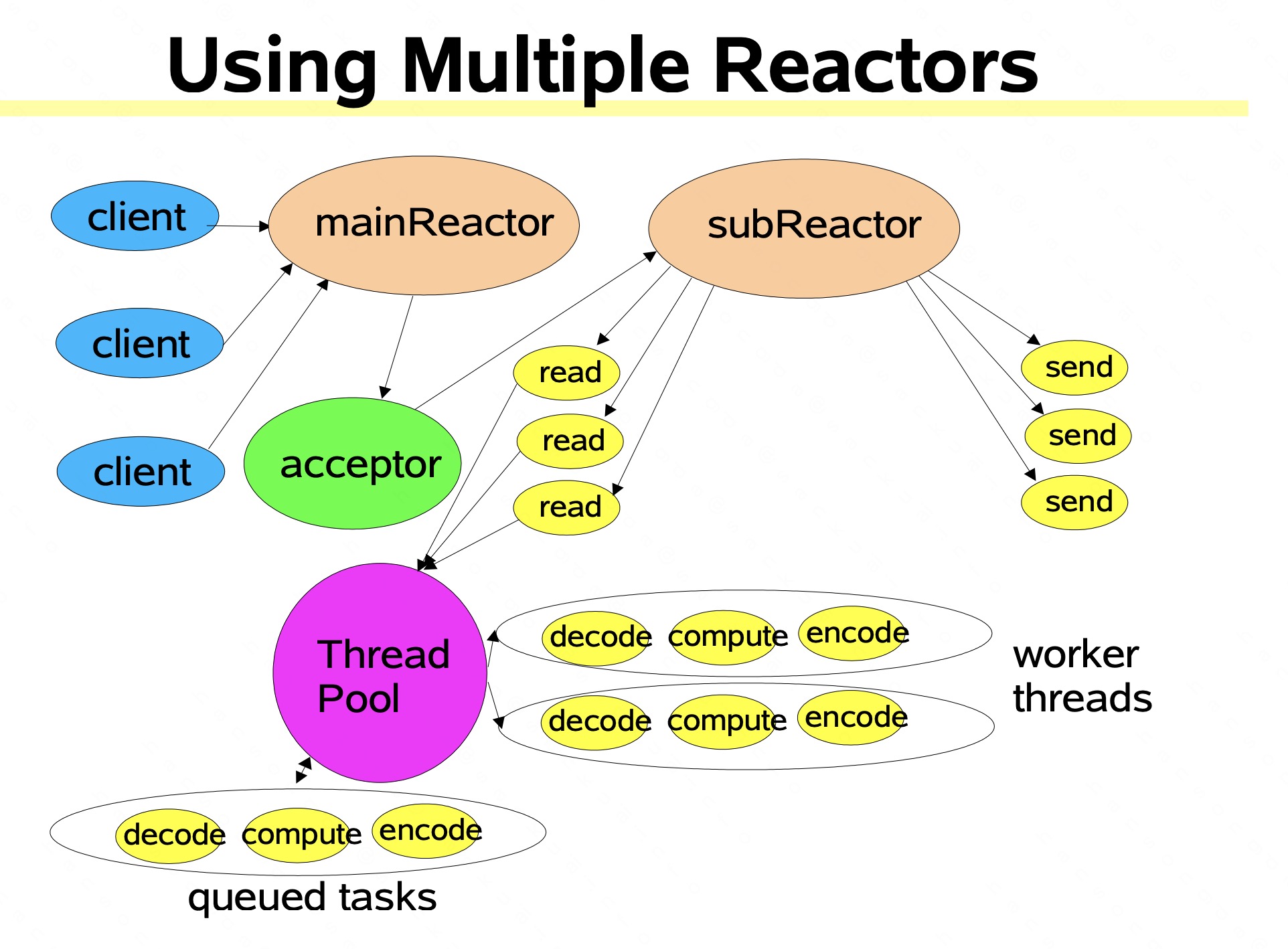
问题七:分区里所有消息都能被消费者看到么?kafka中高水位是什么?
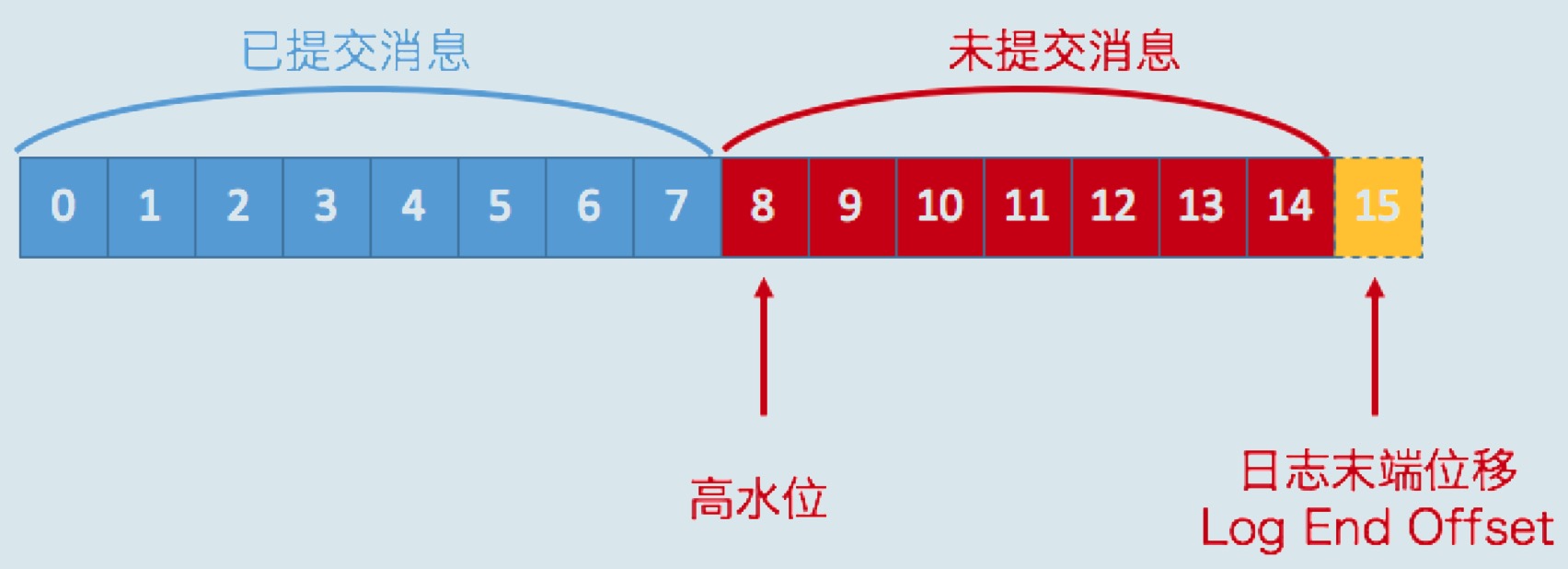
高水位和LEO是副本对象的两个重要属性。 Kafka所有副本都有对应的高水位和LEO值,而不仅仅是Leader副本。只不过Leader副本比较特殊,Kafka使用Leader副本的高水位来定义所在分区的高水位。换句话说,分区的高水位就是其Leader副本的高水位。
我们分别从Leader副本和Follower副本两个维度,来总结一下高水位和LEO的更新机制。
Leader副本
处理生产者请求的逻辑如下:
-
写入消息到本地磁盘。
-
更新分区高水位值。 i. 获取Leader副本所在Broker端保存的所有远程副本LEO值(LEO-1,LEO-2,……,LEO-n)。 ii. 获取Leader副本高水位值:currentHW。 iii. 更新 currentHW = max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)}。
处理Follower副本拉取消息的逻辑如下:
- 读取磁盘(或页缓存)中的消息数据。
- 使用Follower副本发送请求中的位移值更新远程副本LEO值。
- 更新分区高水位值(具体步骤与处理生产者请求的步骤相同)。
Follower副本
从Leader拉取消息的处理逻辑如下:
- 写入消息到本地磁盘。
- 更新LEO值。
- 更新高水位值。 i. 获取Leader发送的高水位值:currentHW。 ii. 获取步骤2中更新过的LEO值:currentLEO。 iii. 更新高水位为min(currentHW, currentLEO)。
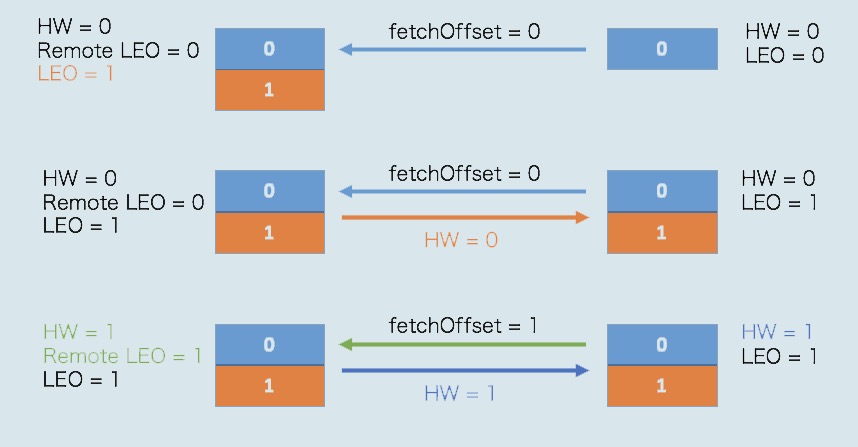
问题八:Leader Epoch的引入是解决什么问题的?
引入Leader Epoch概念,来规避因高水位更新错配导致的各种不一致问题。
所谓Leader Epoch,我们大致可以认为是Leader版本。它由两部分数据组成。
Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的Leader被认为是过期Leader,不能再行使Leader权力。
起始位移(Start Offset)。Leader副本在该Epoch值上写入的首条消息的位移。
todo需要重看这里 加深理解
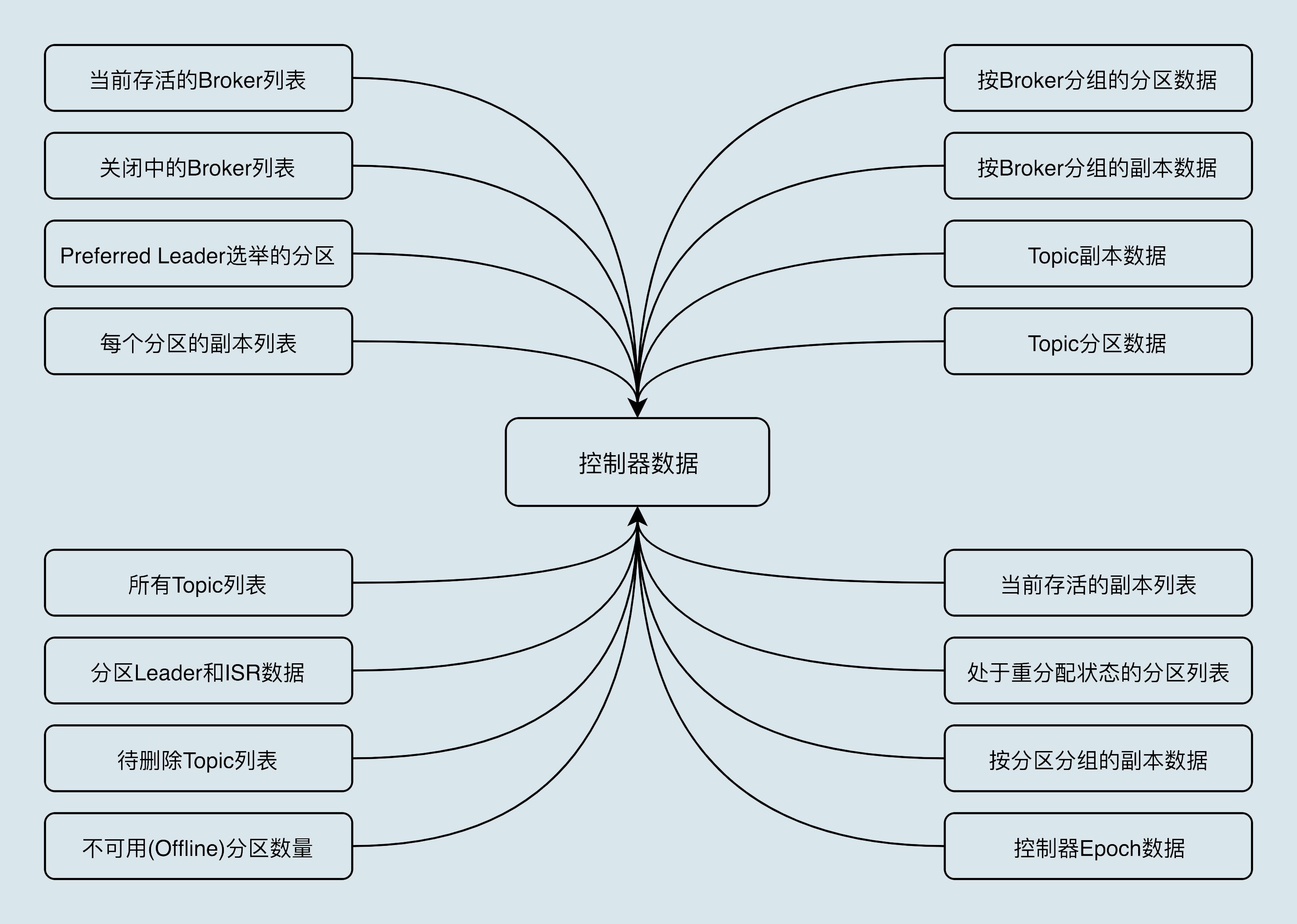
问题九:Kafka的控制器怎么理解?做了什么事情?
控制器组件(Controller),是Apache Kafka的核心组件。它的主要作用是在Apache ZooKeeper的帮助下管理和协调整个Kafka集群。 每个正常运转的Kafka集群,在任意时刻都有且只有一个控制器。控制器是集群粒度的, Kafka当前选举控制器的规则是:第一个成功创建/controller节点的Broker会被指定为控制器。
控制器保存了什么数据?
- 所有主题信息。包括具体的分区信息,比如领导者副本是谁,ISR集合中有哪些副本等。
- 所有Broker信息。包括当前都有哪些运行中的Broker,哪些正在关闭中的Broker等。
- 所有涉及运维任务的分区。包括当前正在进行Preferred领导者选举以及分区重分配的分区列表。
值得注意的是,这些数据其实在ZooKeeper中也保存了一份。
参考
- 《Kafka核心技术与实战》
- 《Kafka核心源码解读》
- Scalable IO in Java - by Doug Lea