Linux内核之进程管理
导读
进程,是操作系统中一个非常基础,非常关键的抽象概念,它位于现代操作系统的核心位置,它是把运行的程序和所需的资源抽象出来的一个概念。 线程,内核又是如何管理的?它和进程有怎么样的关系。
程序和进程的区别: 程序本身不是进程,进程是运行中的程序以及相关资源的总称。 进程与线程的关系: Linux下线程也是进程,和其他进程与进程之间地址空间隔离不同之处在于线程组会共享这个进程的资源、地址空间,线程有自己独立的pc、内核栈。
进程描述符 task_struct 、thread_info
进程在Linux操作系统内核中用一个叫task_struct的结构表示,它完整的描述了一个进程。所以其实对内核来说,进程就是一个数据结构。
task_struct的结构体在Linux内核源码的文件中。对32位机器来说,这个结构体大小差不多是1.7KB。
Linux内核源码在github:其中 task_struct 定义在文件 include/linux/sched.h。
这是个很大的结构体,里面描述了进程需要的几乎所有元素。
进程描述符或者说进程由哪些组成的呢? 比如pid、打开的文件(文件描述符)、进程的虚拟地址空间、进程的状态(阻塞、运行、就绪)、信号处理、父进程的描述符、子进程链表等等。
我们可以摘出来task_struct 中这几个元素:
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
#endif
/* -1 unrunnable, 0 runnable, >0 stopped: 进程状态 */
volatile long state;
/* Per task flags (PF_*), defined further below: flags标记 */
unsigned int flags;
/* 内存描述符 地址空间 */
struct mm_struct *mm;
/* 进程状态 */
int exit_state;
int exit_code;
/* pid 进程标识符 */
pid_t pid;
/* Real parent process: 父进程*/
struct task_struct __rcu *real_parent;
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
* 子进程的链表
*/
struct list_head children;
/* Filesystem information: 文件系统信息*/
struct fs_struct *fs;
/* Open file information: 打开文件信息*/
struct files_struct *files;
/* Namespaces: */
struct nsproxy *nsproxy;
/* Signal handlers: 信号处理*/
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
};
进程描述符的重要性不言而喻,因此必须要更高的性能找到它。不同的硬件体系结构不同:有专门的寄存器可以存这个进程描述符的地址,这样获取就非常之快了;没有这个专门寄存器的怎样获取呢?把thread_info结构放到栈底,然后利用栈指针esp获取。
怎么通过栈指针找到进程描述符?
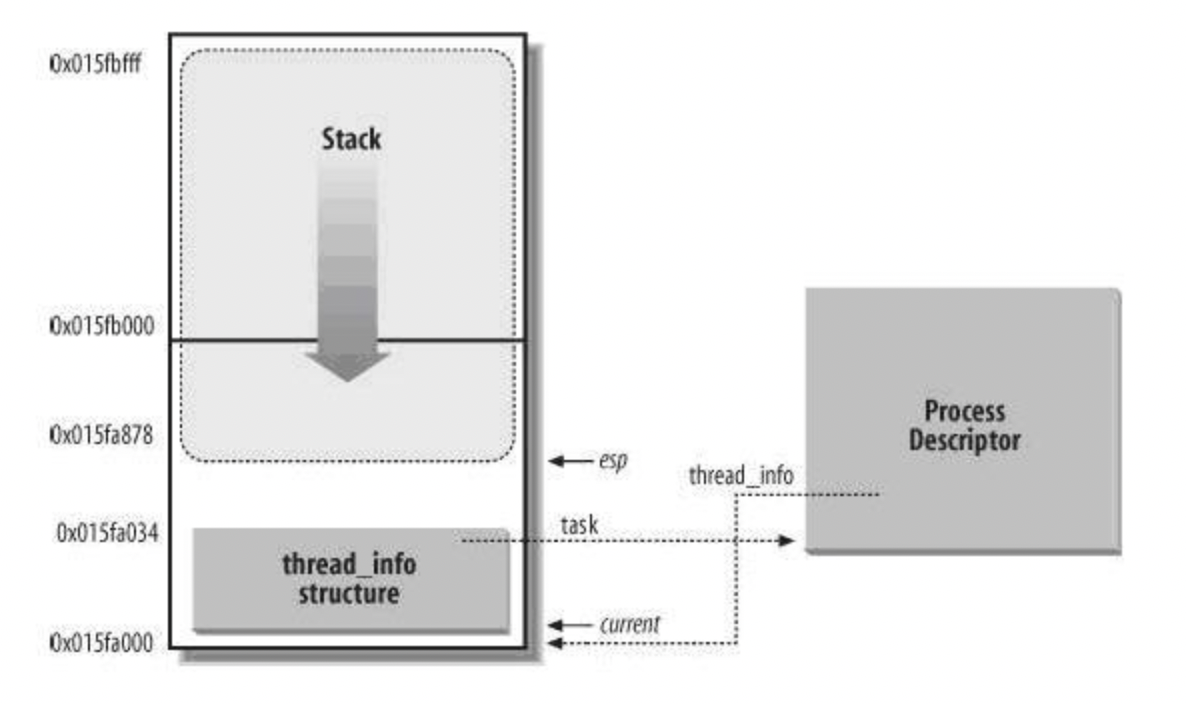
虚拟内存中按页分配,通常是4Kb一个页。内核栈通常8Kb。 如图中的内核栈低地址和高地址:8Kb(2^13)是栈大小(栈低地址:0x15fa000,高地址:0x15fbfff)
低地址的后12位都是0是巧合么?不是的。分配一个页4Kb(2^12),每个页的起始地址都是4K的整数倍,因此这样。 内核栈是8Kb(2^13)大小,因此栈指针的后13位置为0,即是栈底的thread_info地址,继而找到 task_struct进程描述符的地址。
thread_info结构中有task,指向进程描述符。task_struct结构中第一个元素指向thread_info。如图描述亦是如此。
thread_info结构:
struct thread_info {
struct task_struct *task; /* main task structure */
unsigned long flags; /* low level flags */
__u32 cpu; /* current CPU */
int preempt_count; /* 0 => preemptable,
<0 => BUG */
mm_segment_t addr_limit; /* thread address space:
0-0xBFFFFFFF for user
0-0xFFFFFFFF for kernel */
struct thread_info *real_thread; /* Points to non-IRQ stack */
unsigned long aux_fp_regs[FP_SIZE]; /* auxiliary fp_regs to save/restore
them out-of-band */
};
进程状态
进程状态通常分为三种:运行、阻塞、就绪。Linux是分了五种,也可以归类到这三种。 task_struct 中的state 字段描述了进程状态。
又是一图胜千言:

进程家族树
进程之间存在明显的继承关系,所有的进程都是pid为1的init进程的后代(执行 pstree 命令可以查看到)。内核会在系统启动后的做后阶段启动init进程。
每个进程都一定有自己的父进程,也会有0个或者多个子进程。有着同一个父进程的所有进程称为兄弟。上面 task_struct 结构中,内部的parent 即是指向父进程,children是子进程链表。
其实这也解释了为什么fork()函数,返回给父进程的是子进程pid,返回给子进程的是0。因为进程能直接拿到自己的pid和父进程的pid,但是拿不到子进程的具体哪一个pid。
进程创建
那么进程是如何创建的?这里要提到两个关键函数 fork() 和 exec()。(两个函数详细用法可以参考man或者Unix环境高级编程)
fork() 拷贝当前进程创建一个子进程。父子进程区别仅在于pid、ppid(父进程pid)、某些资源和统计量(比如挂起的信号)。
exec() 读取可执行文件并将其载入到地址空间开始运行。
写时拷贝(copy-on-write)
操作系统几乎在所有使用资源的时候,都是采用延迟的策略。
fork()函数过去的实现是会拷贝父进程的所有资源给子进程,这种方式浪费而且低效。比如fork后,子进程马上加载其他的可执行文件,那这个拷贝就都浪费了。
现在Linux的fork()是采用COW机制来延迟拷贝,子进程共享父进程的物理页面。在虚拟内存区域上标记只读来共享,只有到实际发生写入的时候,才会拷贝该页。
fork()的实际开销就是复制父进程的页表,和创建子进程的进程描述符。
fork()的过程
Linux实现fork()是通过叫clone()的系统调用,使用一系列flag参数来指定父子进程共享资源(每个flag细化某种共享资源,比如打开文件、地址空间等)。clone()再去调用do_fork()。
do_fork() 实现在内核源码的 kernel/fork.c 文件。 do_fork()内部会调用copy_process()。
copy_process()函数的几个重点步骤:
一. 拷贝进程描述符。 p = dup_task_struct(current, node); 创建内核栈、thread_info结构和task_struct。此时父子进程的进程描述符是完全一样的。
二. 子进程描述符下的一些成员属性需要被clear或者初始化,比如进程的一些统计信息。大部分成员仍然保持。
三. 内核会校验当前用户分配给的进程数资源限制是否超了。
atomic_read(&p->real_cred->user->processes) >= task_rlimit(p, RLIMIT_NPROC)
四. flags成员设置,比如PF_SUPERPRIV表示有超级用户权限,PF_FORKNOEXEC表示还没调用exec()。
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER |PF_IDLE);
p->flags |= PF_FORKNOEXEC;
五. 根据传入的flags决定是复制还是共享资源。打开文件、文件系统信息、信号控制、地址空间等。比如fork一个线程,这些是共享的。否则会拷贝。
部分代码:
/* copy all the process information */
shm_init_task(p);
retval = security_task_alloc(p, clone_flags);
retval = copy_semundo(clone_flags, p);
// 打开文件
retval = copy_files(clone_flags, p);
// 文件系统
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
// 内存描述符(虚拟内存区域)
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);
retval = copy_thread_tls(clone_flags, stack_start, stack_size, p, tls);
其中值得一说的 拷贝内存描述符 copy_mm(clone_flags, p)
如代码,如果flags传入CLONE_VM,直接使用父进程的内存地址空间(如创建线程);否则会调用dup_mm() 拷贝一份。
copy_mm() 代码:
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
tsk->mm = NULL;
tsk->active_mm = NULL;
/* initialize the new vmacache entries */
vmacache_flush(tsk);
// 如果flags传入CLONE_VM,直接使用父进程的内存地址空间
if (clone_flags & CLONE_VM) {
mmget(oldmm);
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
// 拷贝内存描述符
mm = dup_mm(tsk, current->mm);
if (!mm)
goto fail_nomem;
good_mm:
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
fail_nomem:
return retval;
}
dup_mm() 代码,内部会接着调用 dup_mmap()
/**
* dup_mm() - duplicates an existing mm structure
* @tsk: the task_struct with which the new mm will be associated.
* @oldmm: the mm to duplicate.
*
* Allocates a new mm structure and duplicates the provided @oldmm structure
* content into it.
*
* Return: the duplicated mm or NULL on failure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk, struct mm_struct *oldmm)
{
struct mm_struct *mm;
int err;
mm = allocate_mm();
if (!mm)
goto fail_nomem;
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
if (err)
goto free_pt;
mm->hiwater_rss = get_mm_rss(mm);
mm->hiwater_vm = mm->total_vm;
if (mm->binfmt && !try_module_get(mm->binfmt->module))
goto free_pt;
return mm;
free_pt:
/* don't put binfmt in mmput, we haven't got module yet */
mm->binfmt = NULL;
mm_init_owner(mm, NULL);
mmput(mm);
fail_nomem:
return NULL;
}
六. 给子进程分配一个pid。 pid = alloc_pid(p->nsproxy->pid_ns_for_children);
七. 等等其他工作,最后返回这个task_struct指针p。
fork()返回的父子进程,我们希望优先执行哪一个呢?是子进程。因为子进程通常会exec()另一个和父进程不相关的可执行文件,这样可以避免父进程优先执行写操作而带来的写时复制的开销。
线程的实现
线程机制也是编程技术中常用的一个抽象概念,提供了同一个程序内共享地址空间运行,共享打开的文件等资源。支持单核下并发,多核下可真正并行处理。
Linux的线程实现机制与Windows等其他操作系统不同,Linux并没有非常区别对待线程与进程,线程也同样创建 task_struct结构,但线程会共享同一个地址空间等资源。
创建线程和创建普通的进程区别在于传给clone()的标志参数。
创建线程
传递的flags参数: clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGCHAND, 0);
创建进程时传入了这flags,共享了地址空间、文件系统信息、打开的文件、信号处理程序。这就是创建线程了。这些标志参数决定了新创建进程的行为方式和父子进程之间共享的资源种类。
普通的创建进程fork() 传入的参数:clone(SIGCHLD, 0);
clone参数标志
| 标志(部分) | 含义 |
|---|---|
| CLONE_FILES | 父子进程共享打开的文件 |
| CLONE_FS | 父子进程共享文件系统信息 |
| CLONE_VM | 父子进程共享地址空间 |
| CLONE_SIGCHAND | 父子进程共享信号处理函数和被阻塞信号 |
| CLONE_VFORK | 调用vfork() 父进程准备睡眠等待子进程将其唤醒 |
内核线程
内核也经常有运行在后台的任务,通过内核线程来完成。内核线程是独立运行在内核态的标准进程,区别在于 内核线程没有独立的地址空间(mm成员指向NULL) 。只在内核空间运行,不会切换到用户空间。一样可以被调度和被抢占。
进程终结
比如程序显示调用exit(),或者main()中return来隐式调用都是来终结当前进程。
进程结束时,内核会释放掉它占用的资源并通知它的父进程。进程终结函数 do_exit() 在内核源码的 kernel/exit.c文件。
部分代码
主要操作:释放资源+修改task_struct成员+通知父进程
void __noreturn do_exit(long code)
{
struct task_struct *tsk = current;
exit_signals(tsk); /* sets PF_EXITING */
// task_struct的退出code,供父进程检索
tsk->exit_code = code;
// 释放占用的内存描述符mm_struct,如果没有共享这个地址空间,则彻底释放
exit_mm();
// 退出等待队列
exit_sem(tsk);
exit_shm(tsk);
// 递减文件描述符、文件系统的引用计数。如果引用计数降为0,没有被其他进程使用,则可以释放。
exit_files(tsk);
exit_fs(tsk);
exit_task_namespaces(tsk);
exit_task_work(tsk);
exit_thread(tsk);
exit_umh(tsk);
// 给父进程发信号
exit_notify(tsk, group_dead);
}
进程do_exit()后已经不能再被调度运行了,但是仍然给终结进程设置它的task_struct,保留了它的进程描述符,说明内核还并没有全部释放它所占的资源,包括内核栈、thread_info、task_struct。它还存在的意义是什么?
答案是要给父进程参考,提供给父进程信息比如退出的状态等。父进程检索到信息后(调用wait()系列函数)或者通知内核那是无所谓的信息,内核才会把进程描述符等剩余的内存释放掉。
有一个问题是,如果父进程早于这个子进程终结了,那么岂不是没人回收这些僵尸进程的进程描述符,导致内存泄露了?其实内核会给它找养父,先在这个子进程的线程组里找,如果没有就安排祖宗进程init进程来接管,init进程会例行调用wait()来清除僵尸进程。
Okay,Linux的进程管理就写到这里,理解好进程管理,还要理解虚拟内存。
参考:
- 《Linux内核设计与实现》
- 《深入理解计算机系统》
- Linux内核源码