Redis基础知识
数据结构和应用场景
-
String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
使用自定义字符串结构体,方便O(1)知道长度、拼接字符串不会造成缓冲区溢出、不仅可以保存文本数据,还可以保存二进制数据
-
List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
List 类型的底层数据结构是由双向链表或压缩列表实现的。
-
Hash 类型:缓存对象、购物车等。
Hash 类型的底层数据结构是由压缩列表或哈希表实现的。
-
Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
Set 类型的底层数据结构是由哈希表或整数集合实现的。
-
Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Zset 类型的底层数据结构是由压缩列表或跳表实现的。
-
BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
-
HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
-
GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
-
Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
IO模型
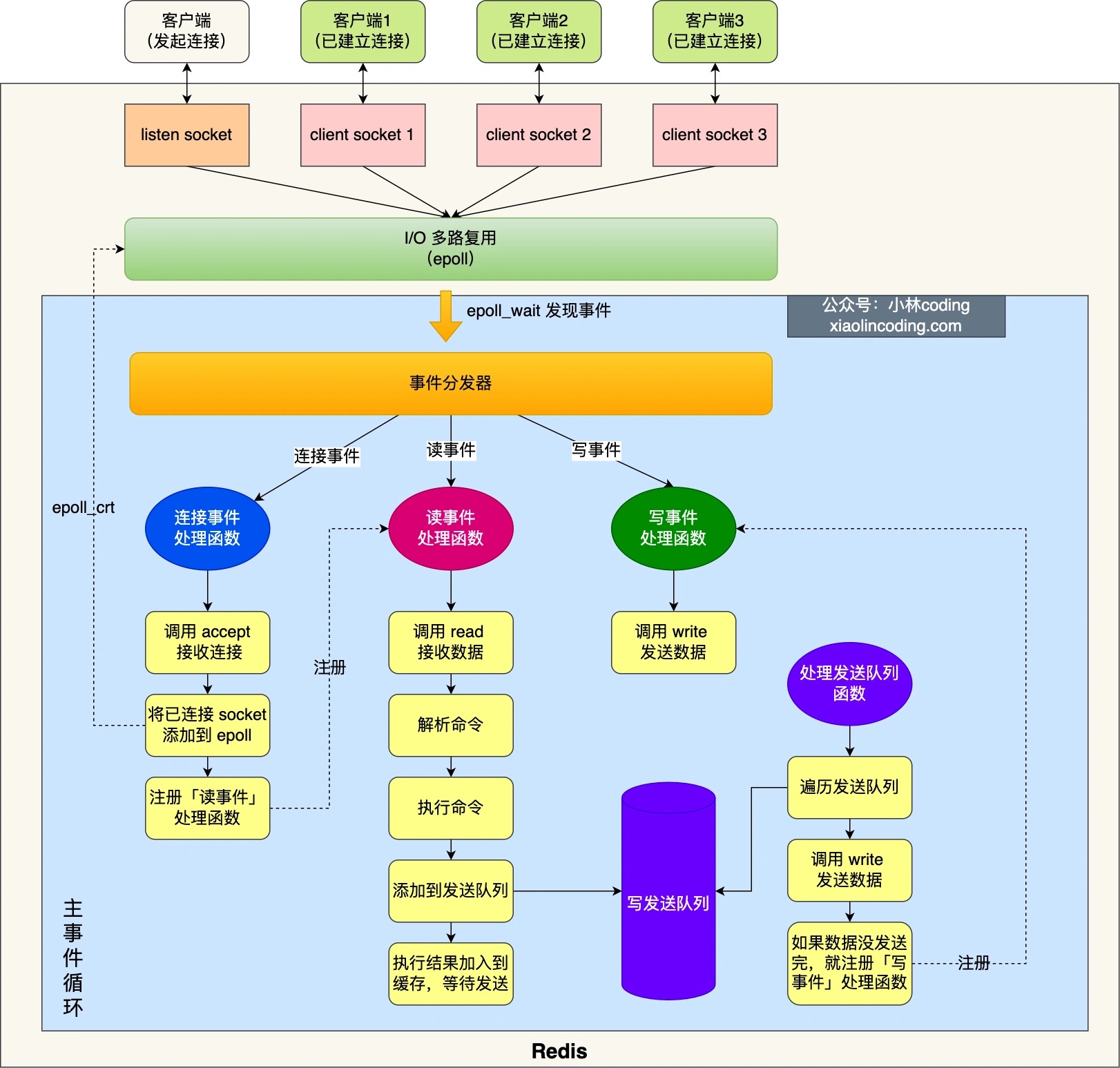
图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程。 Redis 初始化的时候,会做下面这几件事情:
- 首先,调用 epoll_create() 创建一个 epoll 对象和调用 socket() 创建一个服务端 socket
- 然后,调用 bind() 绑定端口和调用 listen() 监听该 socket;
- 然后,将调用 epoll_ctl() 将 listen socket 加入到 epoll,同时注册「连接事件」处理函数。
初始化完后,主线程就进入到一个事件循环函数,主要会做以下事情:
-
首先,先调用处理发送队列函数,看是发送队列里是否有任务,如果有发送任务,则通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
-
接着,调用 epoll_wait 函数等待事件的到来:
- 如果是连接事件到来,则会调用连接事件处理函数,该函数会做这些事情:调用 accpet 获取已连接的 socket -> 调用 epoll_ctl 将已连接的 socket 加入到 epoll -> 注册「读事件」处理函数;
- 如果是读事件到来,则会调用读事件处理函数,该函数会做这些事情:调用 read 获取客户端发送的数据 -> 解析命令 -> 处理命令 -> 将客户端对象添加到发送队列 -> 将执行结果写到发送缓存区等待发送;
- 如果是写事件到来,则会调用写事件处理函数,该函数会做这些事情:通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会继续注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
当Redis server创建Socket后,就会注册可读事件,并使用acceptTCPHandler回调函数处理客户端的连接请求。
当server和客户端完成连接建立后,server会在已连接套接字上监听可读事件,并使用readQueryFromClient函数处理客户端读写请求。这里,无论客户端发送的请求是读或写操作,对于server来说,都是要读取客户端的请求并解析处理。 所以,server在客户端的已连接套接字上注册的是可读事件。
而当实例需要向客户端写回数据时,实例会在事件驱动框架中注册可写事件,并使用sendReplyToClient作为回调函数,将缓冲区中数据写回客户端。
epoll redis-demo
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
epfd = epoll_create(EPOLL_SIZE); //创建epoll实例,
//创建epoll_event结构体数组,保存套接字对应文件描述符和监听事件类型
ep_events = (epoll_event*)malloc(sizeof(epoll_event) * EPOLL_SIZE);
//创建epoll_event变量
struct epoll_event ee
//监听读事件
ee.events = EPOLLIN;
//监听的文件描述符是刚创建的监听套接字
ee.data.fd = sock_fd;
//将监听套接字加入到监听列表中
epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &ee);
while (1) {
//等待返回已经就绪的描述符
n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
//遍历所有就绪的描述符
for (int i = 0; i < n; i++) {
//如果是监听套接字描述符就绪,表明有一个新客户端连接到来
if (ep_events[i].data.fd == sock_fd) {
conn_fd = accept(sock_fd); //调用accept()建立连接
ee.events = EPOLLIN;
ee.data.fd = conn_fd;
//添加对新创建的已连接套接字描述符的监听,监听后续在已连接套接字上的读事件
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ee);
} else { //如果是已连接套接字描述符就绪,则可以读数据
...//读取数据并处理
}
}
}
fork进程
fork进程后,不阻塞原主线程执行,但执行fork进程本身会阻塞。
- AOF 执行重写时,主线程fork出后台的 bgrewriteaof 子进程。
- RDB文件生成时,bgsave 创建一个子进程,避免了主线程的阻塞,这也是Redis RDB文件生成的默认配置。
分片集群和slot
在应对数据量扩容时,虽然增加内存这种纵向扩展的方法简单直接,但是会造成数据库的内存过大,导致性能变慢。Redis切片集群提供了横向扩展的模式,也就是使用多个实例,并给每个实例配置一定数量的哈希槽,数据可以通过键的哈希值映射到哈希槽,再通过哈希槽分散保存到不同的实例上。这样做的好处是扩展性好,不管有多少数据,切片集群都能应对。
在Redis Cluster方案中,一个切片集群共有16384个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的key,被映射到一个哈希槽中。
具体的映射过程分为两大步:首先根据键值对的key,按照CRC16算法计算一个16 bit的值;然后,再用这个16bit值对16384取模,得到0~16383范围内的模数,每个模数代表一个相应编号的哈希槽。(在手动分配哈希槽时,需要把16384个槽都分配完,否则Redis集群无法正常工作)
通过哈希槽,切片集群就实现了数据到哈希槽、哈希槽再到实例的分配。但是,即使实例有了哈希槽的映射信息,客户端又是怎么知道要访问的数据在哪个实例上呢?
客户端为什么可以在访问任何一个实例时,都能获得所有的哈希槽信息呢?这是因为,Redis实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。
客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。
redis实例和哈希槽随着实例上下线、负载变化,也会跟着发生变化。实例之间可以互通,但客户端需要感知变化。这里Redis Cluster方案提供了一种重定向机制,所谓的“重定向”,就是指,客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令,如MOVED和ASK命令。
分布式锁
- 加锁形式
setnx + 超时时间 SET key value [EX seconds | PX milliseconds] [NX]
2.如何避免被其他线程解锁?
value 可以设置 ip+线程id
- 删除原子性?
删除要先判断值是不是当前ip+线程id,是再删。这里有两个命令get()+del(),因此可以用lua脚本。
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
redis-cli --eval unlock.script lock_key , unique_value
- 基于多个节点的实现高可靠的分布式锁?
Redlock算法:
- 客户端获取当前时间。
- 客户端按顺序依次向N个Redis实例执行加锁操作。 失败继续下一个,超过一半即可
- 一旦客户端完成了和所有Redis实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
缓存到期和淘汰策略
- 缓存容量设置?
建议把缓存容量设置为总数据量的15%到30%,兼顾访问性能和内存空间开销。
如设置缓存容量4g: CONFIG SET maxmemory 4gb
到期策略
Redis 使用的过期删除策略是 「惰性删除+定期删除」 这两种策略配和使用。
每当我们对一个 key 设置了过期时间时,Redis 会把该 key 带上过期时间存储到一个过期字典(expires dict)中,也就是说「过期字典」保存了数据库中所有 key 的过期时间。
淘汰策略
-
默认不淘汰,满了再写自然就报错
-
淘汰策略
(1)从设置了过期时间的key中淘汰
- volatile-random 在设置了过期时间的键值对中,进行随机删除。
- volatile-ttl 根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-lru LRU算法 最近最少访问的key
- volatile-lfu LFU算法 带频率统计的
(2)全集中淘汰
- allkeys-random 从所有键值对中随机选择并删除数据;
- allkeys-lru 使用LRU算法在所有数据中进行筛选
- allkeys-lfu 使用LFU算法在所有数据中进行筛选
2.1. LRU:双向链表+哈希表 这种实现比较耗费内存空间资源,Redis实现LRU做了简化。如下:
Redis默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构RedisObject中的lru字段记录)。然后,Redis在决定淘汰的数据时,第一次会随机选出N个数据,把它们作为一个候选集合。接下来,Redis会比较这N个数据的lru字段,把lru字段值最小的数据从缓存中淘汰出去。
2.2. LFU:小顶堆(频率小的在top被淘汰)+哈希表 或者 双层哈希表(key→节点、freq→节点链表)
Redis实现也不是严格按LFU的数据结构来,是在key上记录了访问次数和时间戳
2.3. Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。
-
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
-
在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),用来记录 key 的访问时间戳;低 8bit 存储 logc(Logistic Counter),用来记录 key 的访问频次。
2.4. 扩展LRU、LFU对比
LRU 核心结构:哈希表 + 双向链表,核心是「按使用时间排序」,淘汰最久未用的项,所有操作 O (1);
LFU 核心结构:双层哈希表(key→节点、freq→节点链表)+ min_freq 变量,核心是「按使用频率排序」,同频率按 LRU 淘汰,所有操作 O (1);
AOF、RDB
AOF
记录的是Redis收到的每一条命令,这些命令是以文本形式保存的。
三种写回策略
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘; 基本不丢失;影响性能
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘; 宕机可能秒级别丢失
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。 同样可能丢失
AOF一直追加写,文件很大怎么解决的
AOF重写机制,多次操作同一个key可以合并
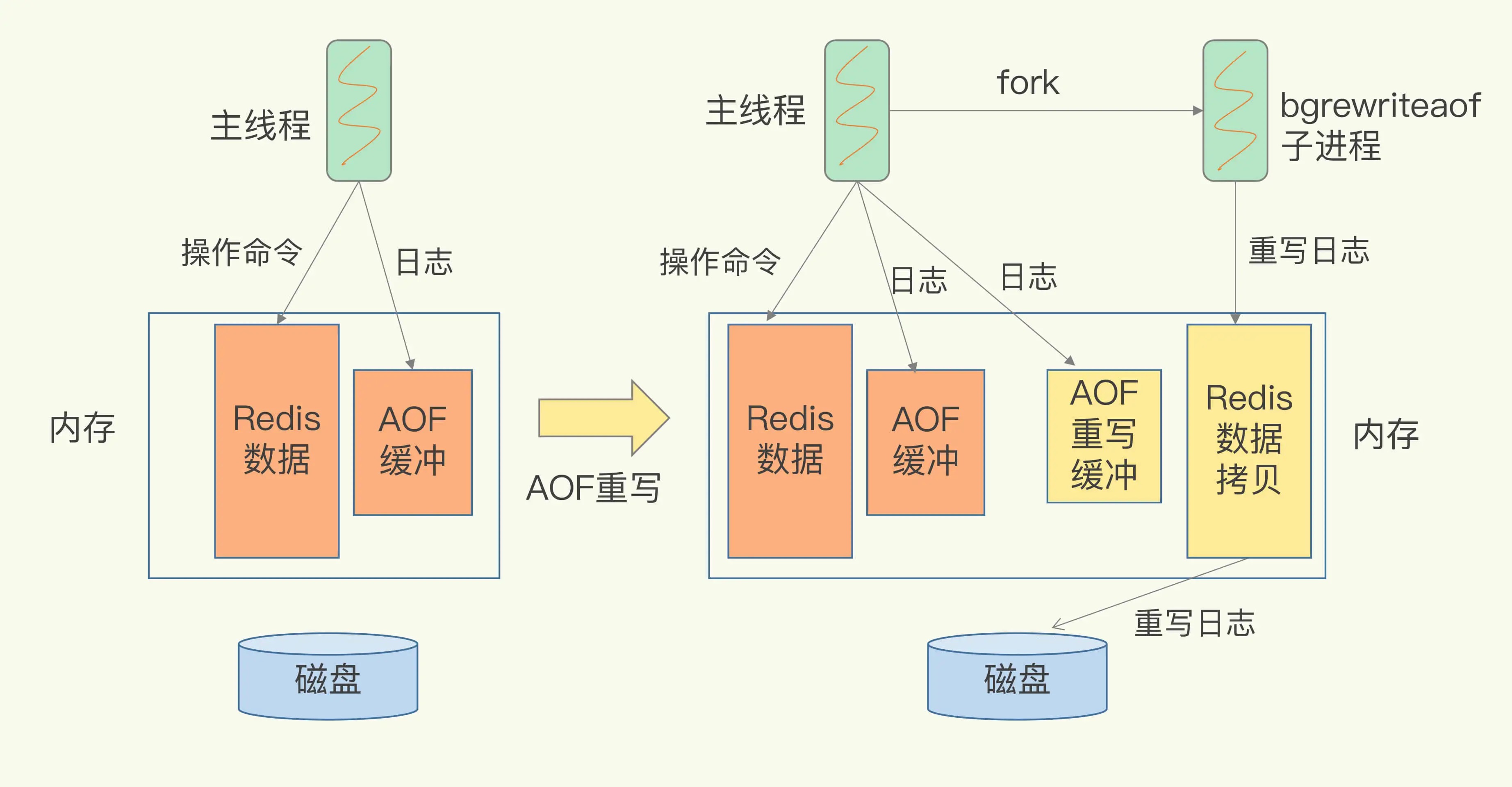
AOF重写线程模型是啥样的?如图:
和AOF日志由主线程写回不同,重写过程是由后台子进程bgrewriteaof来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。
RDB
恢复时,AOF一条一条执行比较慢,可以内存快照的形式RDB。
Redis提供了两个命令来生成RDB文件,分别是save和bgsave。
- save:在主线程中执行,会导致阻塞;
- bgsave:创建一个子进程,专门用于写入RDB文件,避免了主线程的阻塞,这也是Redis RDB文件生成的默认配置。
bgsave子进程是由主线程fork生成的,可以共享主线程的所有内存数据。bgsave子进程运行后,开始读取主线程的内存数据,并把它们写入RDB文件。
应用写时复制技术(Copy-On-Write, COW),如果主线程对这些数据也都是读操作,那么,主线程和bgsave子进程相互不影响。 如果主线程要修改一块数据,那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave子进程会把这个副本数据写入RDB文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
RDB备份频率低,可能丢数据,备份频率高,fork时阻塞影响性能。
Redis 4.0中提出了一个混合使用AOF日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用AOF日志记录这期间的所有命令操作。
如何实现统计需求
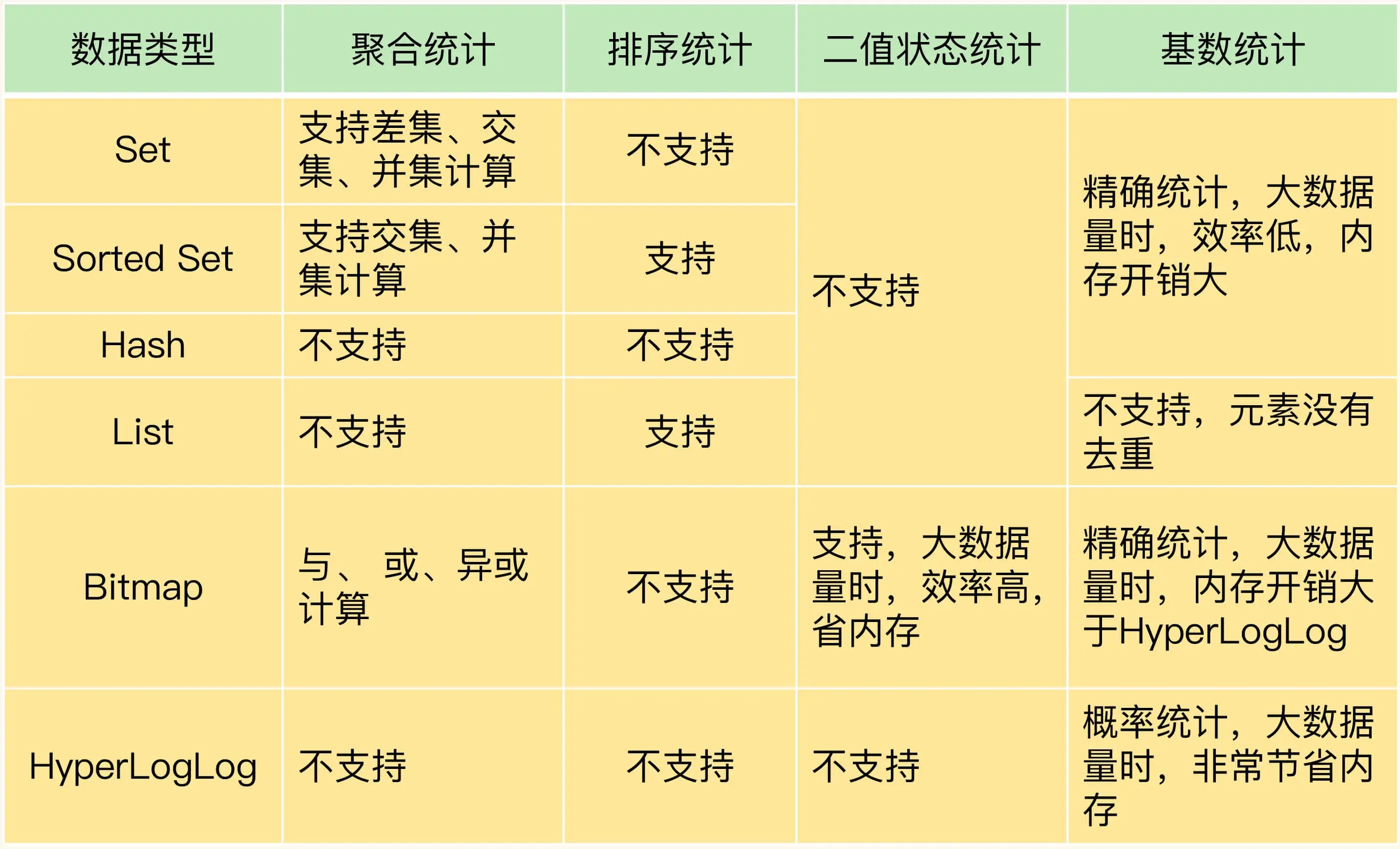
聚合统计
集合做交差并:
- 交(SINTERSTORE)
- 差(SDIFFSTORE)
- 并(SUNIONSTORE)
Set的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致Redis实例阻塞。
可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。
排序统计
List和Sorted Set属于有序集合。List是按照元素进入List的顺序进行排序的,而Sorted Set可以根据元素的权重来排序。
SortedSet的ZRANGEBYSCORE 按权重排序。一些应用场景,比如按时间排序、按数量排等。
二值状态统计
bitmap的应用。
二值状态就是指集合元素的取值就只有0和1两种。在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
举例:在签到统计时,每个用户一天的签到用1个bit位就能表示,一个月(假设是31天)的签到情况用31个bit位就可以,而一年的签到也只需要用365个bit位,根本不用太复杂的集合类型。这个时候,我们就可以选择Bitmap。这是Redis提供的扩展数据类型。
SETBIT key offset value
SETBIT key 2 1
SETBIT key 5 1
SETBIT key 6 0
GETBIT key 2 => 1
BITCOUNT key => 2
基数统计
举例:统计一个页面的UV ?
通常我们可以设计一个集合Set,把用户id放进去,统计个数即可。
当UV量很大时,这个集合自然会非常大,浪费资源。有什么更好的方式?
HyperLogLog是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在Redis中,每个 HyperLogLog只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。这个数据结构实在强大,数学在其中发挥了巨大作用。
使用方法:
PFADD key user1 user2 user3 user4 user5 user6
PFCOUNT key => 6
主从同步
Redis的主从复制主要包括了三种情况:
-
全量复制: 全量复制传输RDB文件
-
增量复制: 增量复制传输主从断连期间的命令
-
长连接同步:长连接同步则是把主节点正常收到的请求传输给从节点
第一次同步

-
从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。 psync命令包含了主库的runID和复制进度offset两个参数。
-
主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的RDB文件。
-
为了保证主从库的数据一致性,主库会在内存中用专门的replication buffer,记录RDB文件生成后收到的所有写操作。
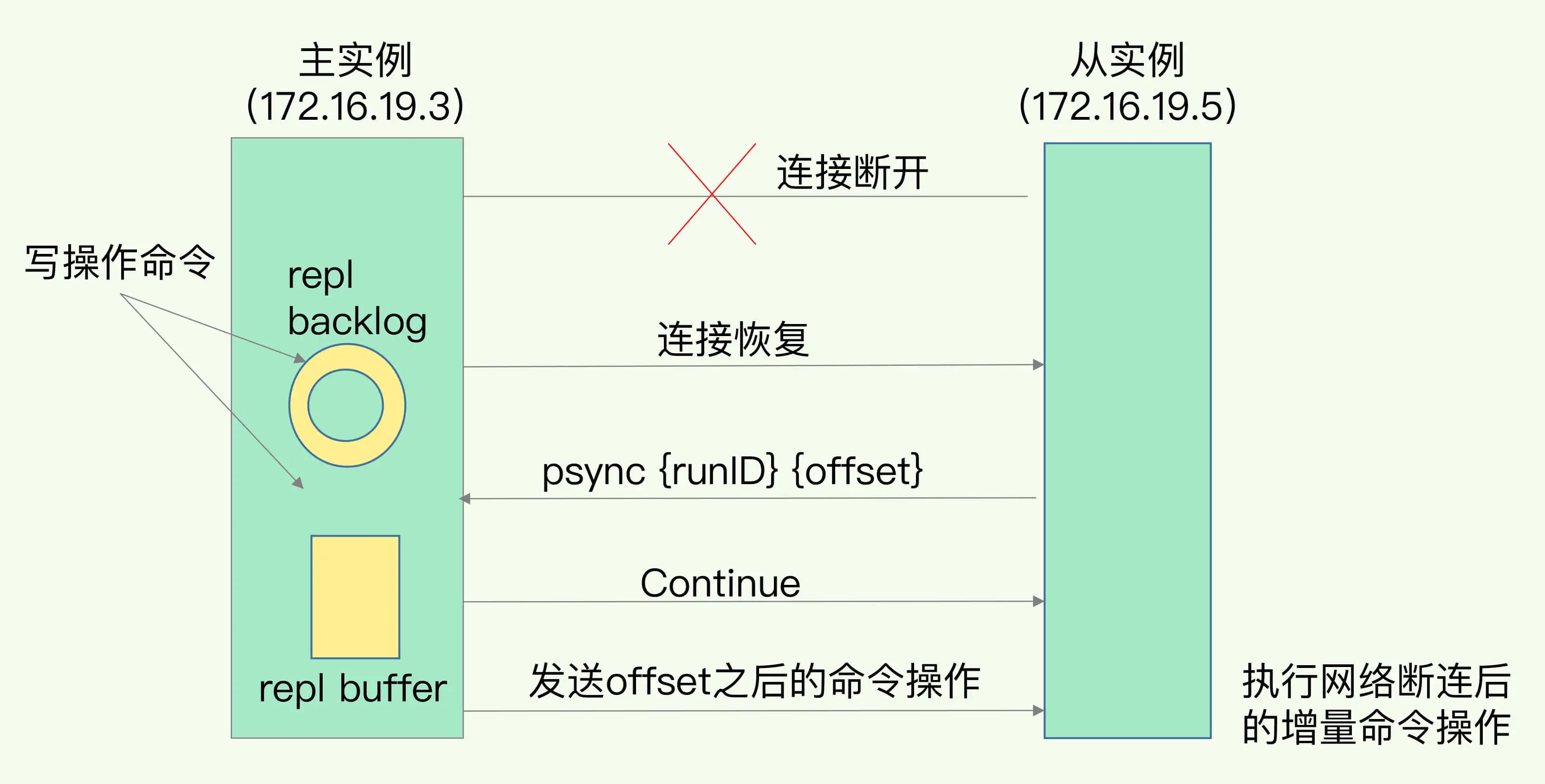
主从断连后的同步
断连接后,主库会把写命令记录到repl_backlog_buffer,这是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
有个问题是,断连接时间长可能环形队列覆盖造成数据丢失,需要适当调整队列长度。
基于状态机的主从复制实现
todo
脑裂问题
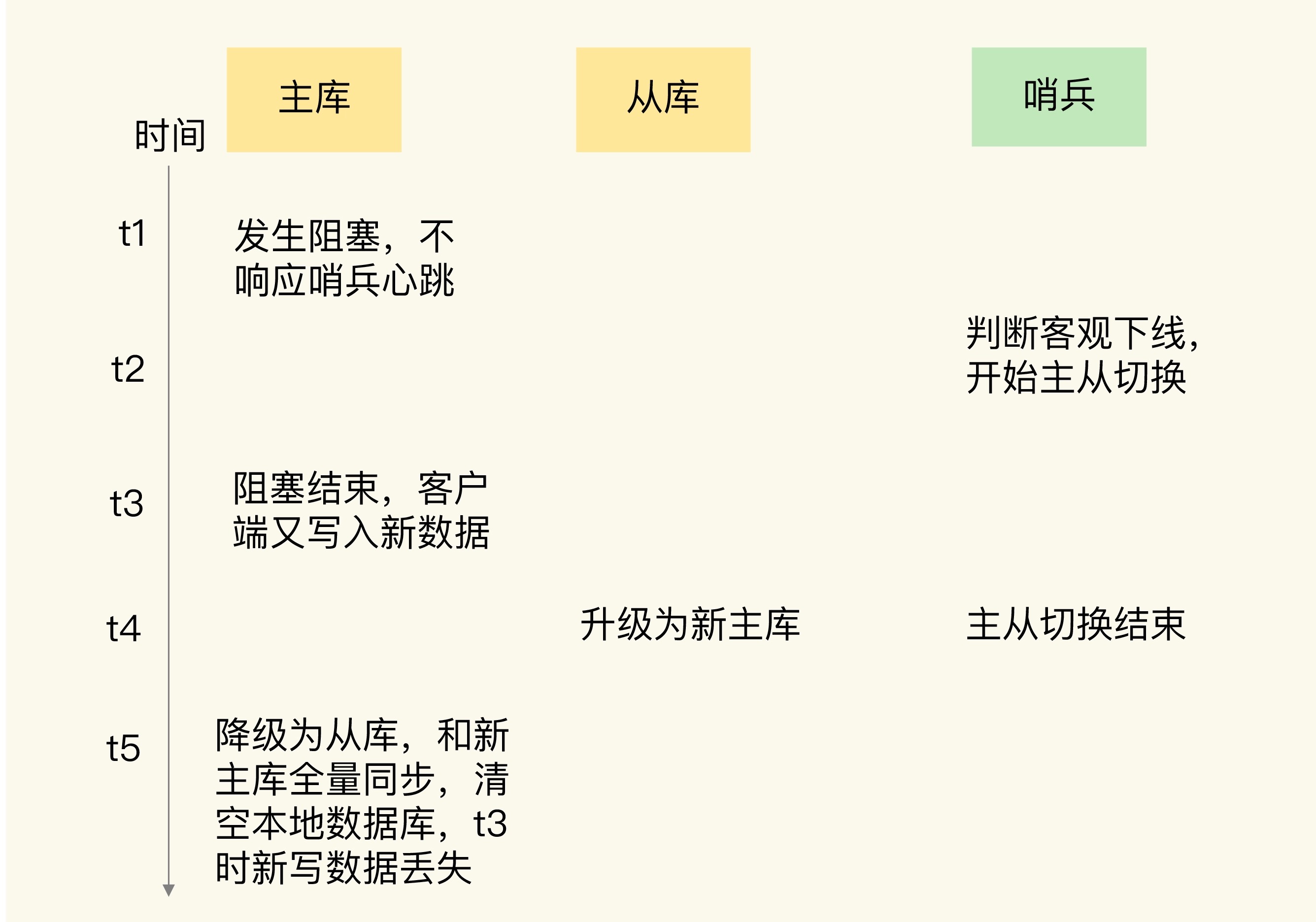
分布式服务CAP中的P即是网络分区,分区导致脑裂问题,意味着有多个主。
Redis脑裂描述:由于网络问题,集群节点之间失去联系。主从数据不同步;重新选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了。
在 Redis 的配置文件中有两个参数我们可以设置:
- min-slaves-to-write x,主节点必须要有至少 x 个从节点连接,如果小于这个数,主节点会禁止写数据。
- min-slaves-max-lag x,主从数据复制和同步的延迟不能超过 x 秒,如果超过,主节点会禁止写数据。
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。
这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的写请求了。
即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足,原主库就会被限制接收客户端写请求,客户端也就不能在原主库中写入新数据了。
等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库,即使它的数据被清空了,也不会有新数据丢失。
哨兵机制
主库挂了,怎么快速切到合适的从库,保证高可用。这样几个问题:
- 主库真的挂了吗?
- 该选择哪个从库作为主库?
- 怎么把新主库的相关信息通知给从库和客户端呢?
引出哨兵机制。
哨兵也是一个redis实例,只不过它负责的是:1. 监控、2. 选主 3. 通知。
-
判断主库挂
哨兵进程会使用PING命令检测它自己和主、从库的网络连接情况,用来判断实例的状态。 从库挂成本小,主库是否挂需要仔细,一个哨兵决策不了,要引出更多的哨兵实例组成哨兵集群一起判断。如超一半以上哨兵判断挂了,认为是挂了。
-
选哪个做新主库
- 检查从库的当前在线状态,还要判断它之前的网络连接状态。
- 优先级最高的从库得分高。slave-priority配置项,一般按机器配置来
- 同步offset越大分越高。
- ID号小的从库得分高。每个实例都会有一个ID,这个ID就类似于这里的从库的编号。
-
通知其他从库和客户端,主库变更了
这就利用了发布订阅pub/sub机制。
3.1 哨兵集群的各实例之间是如何发现的?
哨兵在部署的时候,只知道主库ip+port,不知道其他哨兵。主库上有一个名为“sentinel:hello”的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
3.2 哨兵是如何知道其他从库的?
哨兵向主库发送info命令,主库接受到这个命令后,就会把从库列表返回给哨兵。这样哨兵和从库之间也建立了连接,实现消息通知。
3.3 哨兵如何通知的客户端?
哨兵上有很多频道提供,比如主库切换等,各客户端来订阅这些频道得知事件。比如换主了,那么客户端就会连新的主。
缓存击穿、穿透等问题
-
缓存击穿:key过期了,导致流量都打到db
- 不设置过期时间,由后台任务或者mq或者消费binlog去redis主动改key
- 互斥锁,控制流量。让一个线程去查db更新redis,没拿到锁的返回个默认值
- 双key,一个key带超时时间,一个key不带用来备份
-
缓存穿透:redis和db都没有的数据,也是直接打到db
- 缓存里塞上个默认值
- 布隆过滤器,db有的值放到布隆过滤器一份,利用其一定知道元素不存在
如何实现延迟队列
在Redis可以使用有序集合(ZSet)的方式来实现延迟消息队列的,ZSet 有一个 Score 属性可以用来存储延迟执行的时间。
使用 zadd score1 value1 命令就可以一直往内存中生产消息。再利用 zrangebysocre 查询符合条件的所有待处理的任务, 通过循环执行队列任务即可。
大key问题
大 key 会带来以下四种影响:
- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
- 内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
怎么找到大key
- 第三方开源工具 从rdb文件里找
- scan 自己去遍历 按不同类型找大key
怎么删除大key
- 寻找流量低峰处理
- 集合队列类型可以分批次删除
- 异步删除:用 unlink 命令代替 del 来删除,不阻塞主线程。
hash结构与渐进式rehash
为了让hash表的负载因子维持在一个合理范围,要对哈希表做扩容或收缩。当数据量很大时,这个过程是渐进式的。
hash表的三个结构体定义
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
rehash 图示
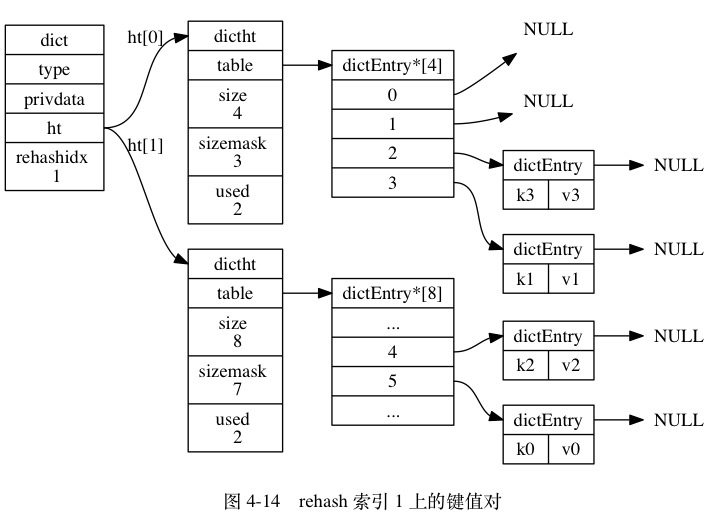
rehash 过程中,对 key 的删除、更新、查找 都会在 ht[0] 和 ht[1] 进行,而 新增key 则只会在ht[1] 进行,保证原hash表只减不增。
有序集合的数据结构-跳表
Redis 的跳跃表由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义:
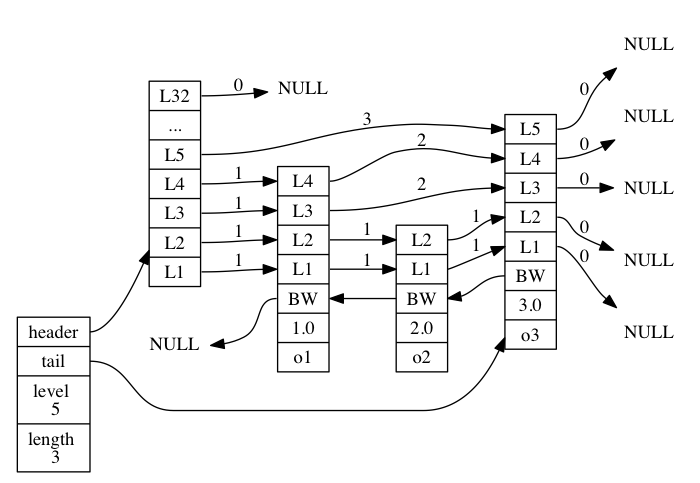
位于图片最左边的是 zskiplist 结构, 该结构包含以下属性:
- header :指向跳跃表的表头节点。
- tail :指向跳跃表的表尾节点。
- level :记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。
- length :记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
zskiplist 结构
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;
redis.h/zskiplistNode 结构
typedef struct zskiplistNode {
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
// 层 注意是个level数组,可以多层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
- 层
跳跃表节点的 level 数组可以包含多个元素, 每个元素都包含一个指向其他节点的指针, 程序可以通过这些层来加快访问其他节点的速度, 一般来说, 层的数量越多, 访问其他节点的速度就越快。
每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。
- 跨度
层的跨度(level[i].span 属性)用于记录两个节点之间的距离。
跨度实际上是用来计算排位(rank)的: 在查找某个节点的过程中, 将沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。
参考资料
- 《Redis核心技术与实战》
- 《Redis源码剖析与实战》
- 《Redis设计与实现》
- 小林coding-Redis