计算机基础-零拷贝
Kafka、Netty、NGINX这些流行的大量涉及IO操作的开源组件都有应用零拷贝的技术,来提升性能。一定好奇零拷贝是什么意思?
read API的流程
假设这样一个场景,服务端从本地磁盘读文件,读到内容写给另一台客户端。这涉及到两次读写IO操作,从磁盘读read(),写网卡write()。
read()、write() 这些是高级抽象的API,底层有很多事要做。操作系统要和硬件打交道就要陷入内核,信息要从内核缓冲区和用户缓冲区拷贝等。
来看read()的流程图:
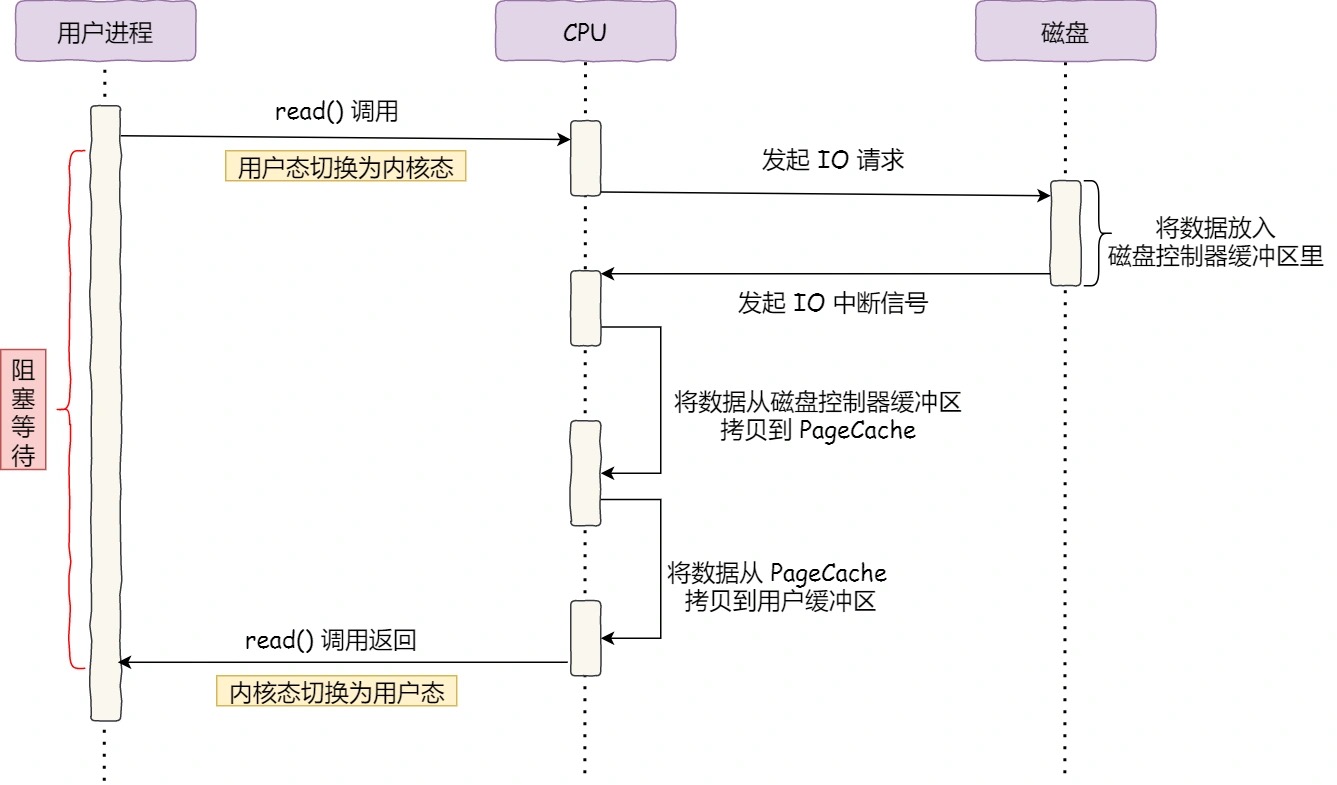
这里的cpu利用率很低,需要参与拷贝字节,而无法响应其它事情。
引出DMA设备控制器,它可以代替CPU拷贝字节,提升效率。
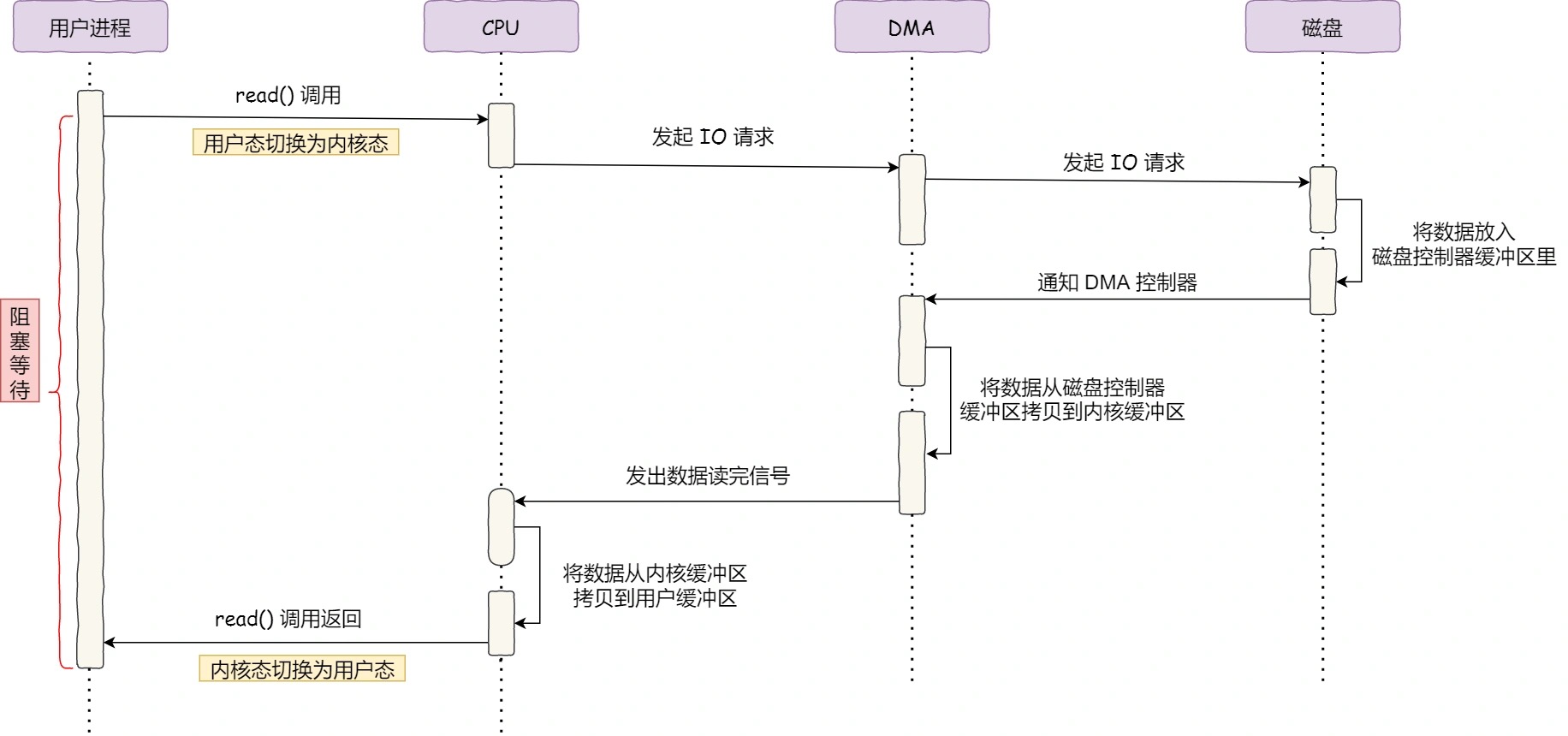
传统读写传输
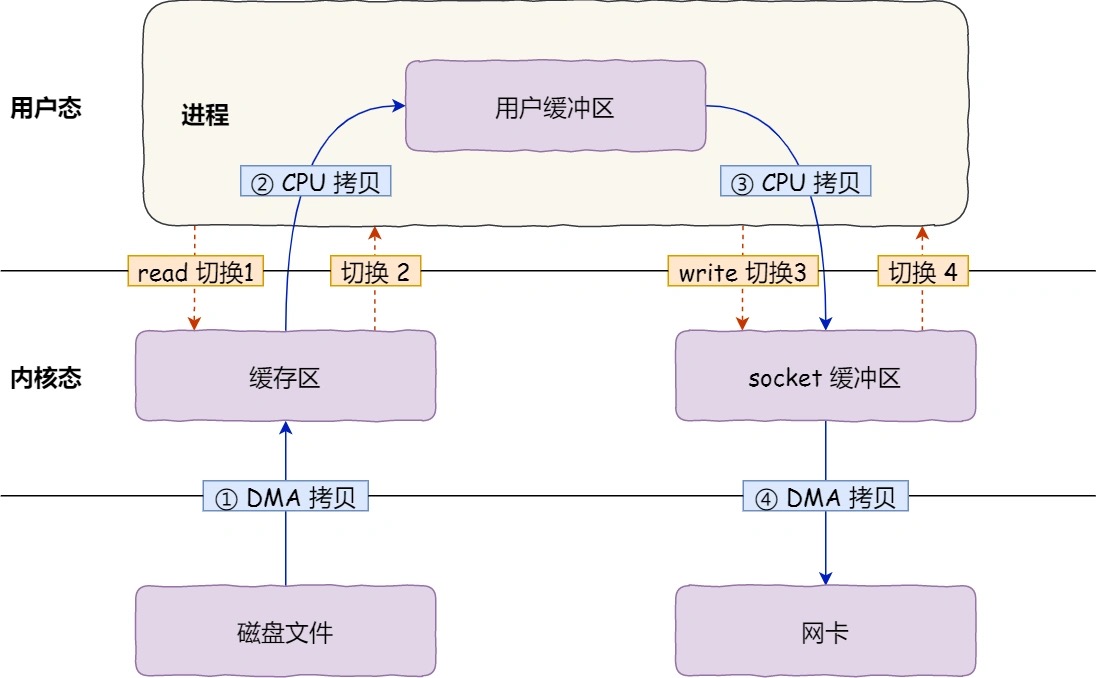
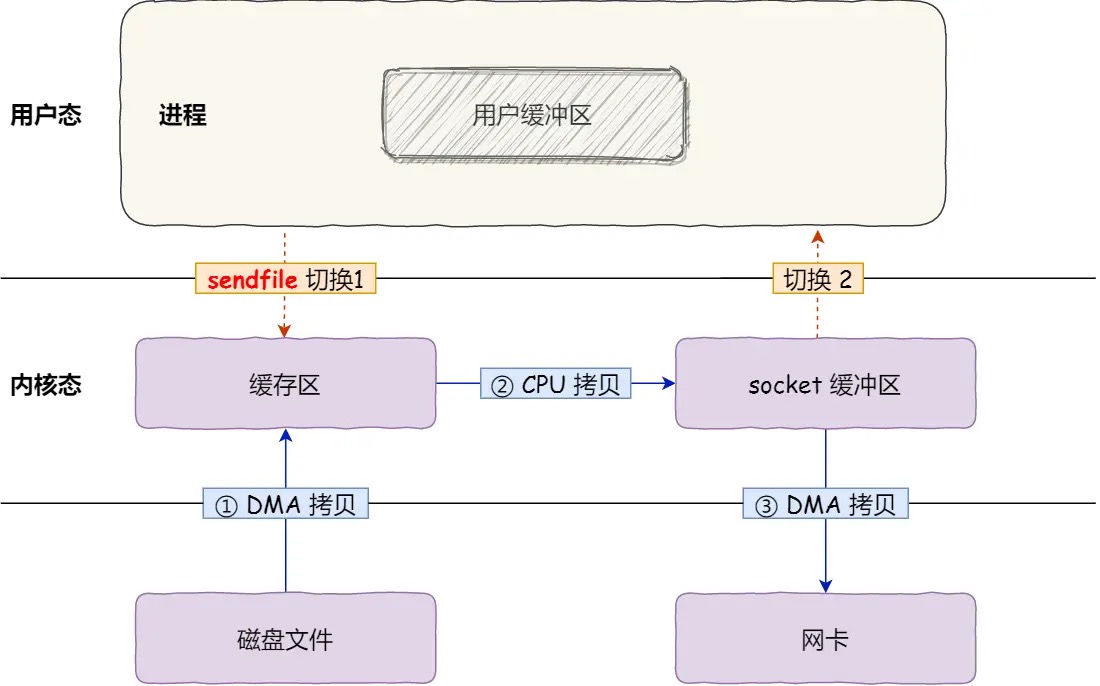
共发生了 4 次用户态与内核态的上下文切换。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
- 把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
- 把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
- 把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
- 把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
零拷贝
零拷贝技术实现的方式通常有 2 种:
- mmap + write
- sendfile
mmap
mmap() 会将一段内存在内核空间和用户空间做一个映射,这样就免去内核到用户空间的拷贝了。系统调用的次数没有变化,还是2次。
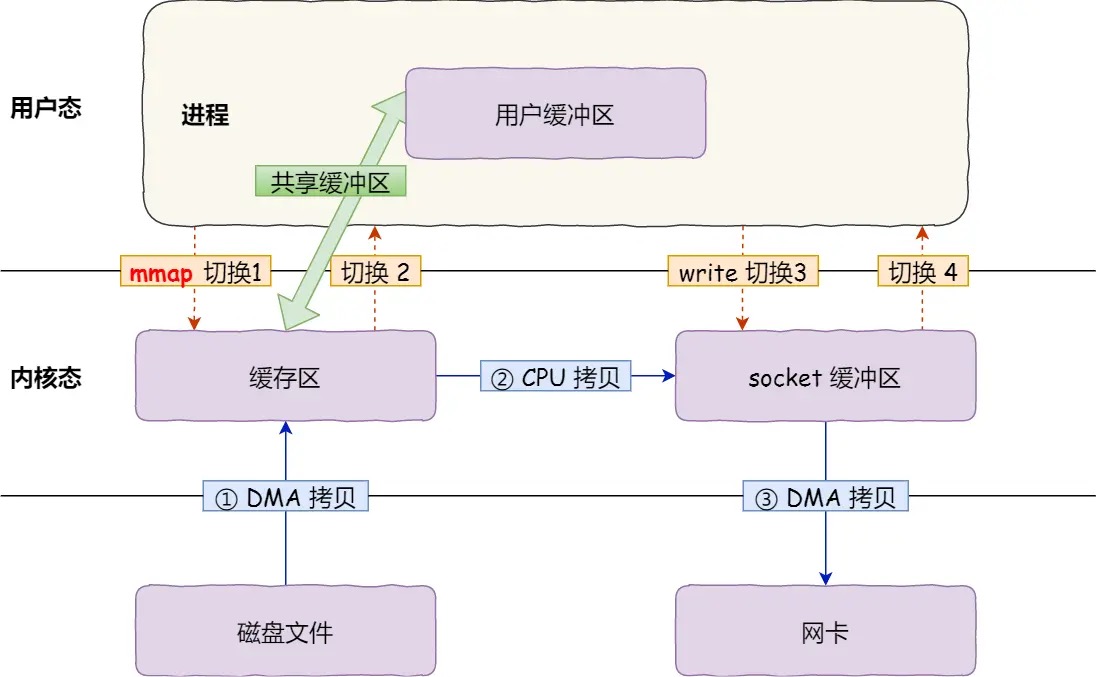
sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),提供入和出两个fd,可以替代read()和write()2次调用变1次。拷贝次数和mmap() 没变化。
ssize_t sendfile(int out_fd,int in_fd,off_t*offset,size_t count);
再优化,拷贝次数能不能再少一次?从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了变化。
具体看第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝。
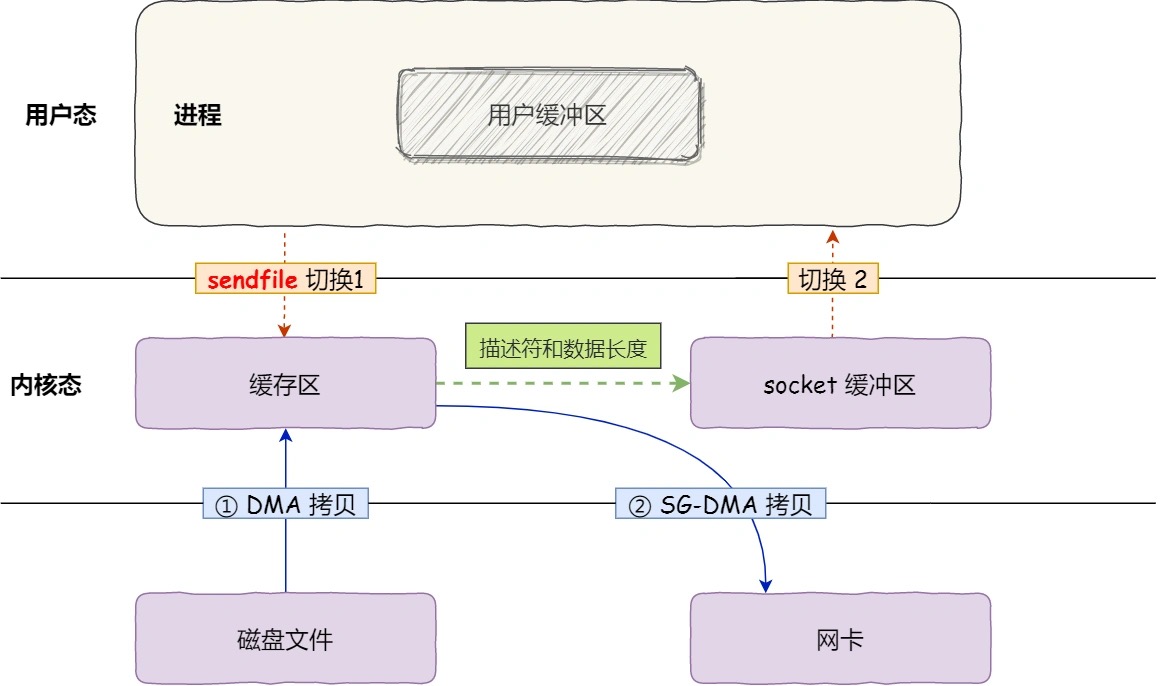
以上就是零拷贝的原理了,这也是软硬件技术提升的产物,硬件需要DMA设备控制器,软件由操作系统给出sendfile系统调用。